ENCOR 350-401|Часть 1.1 - L2/L3 Switching, Forwarding architecture
CCNP ENCOR 
Прошел месяц. Однако. Думал будет быстрее, но, как показала практика, зацепишься за одну тему, всплывет еще с десяток. Копилка с материалами пополнилась несколькими книгами, обзавелось папкой “Доп. материалы” куда я планирую скидывать источники той или иной информации. (RFC, стадндарты, статьи, публикации и т.п).
Да, теория душит, но уже скоро планирую переехать к практике. Уже начал приготовления, даже оживил каталисты 2960 и 2950T!
В этом разделе вышло так, что проскакал по вершкам, иногда ныряя поглубже. В итоге, получилось то, что получилось. Приятного чтения.
С основами монополиста канальной среды разобрались, продолжаем двигаться к современным сетям.
L2 Switching [key-topic]
Коммутатор (switch) - устройства, пришедшие на замену хабам. (в промежутке еще были Мосты (Bridge), но мы их чуть позже еще вспомним).
Принцип работы коммутатора незамысловат и известен каждому - на коммутатор приходит пакет, изучается адрес-источника, вносится в таблицу(цы) MAC-адресов, состоящую из MAC-адреса, порта и назначенного VLAN. После производятся некоторые действия с кадром и он отправляется куда нужно.
Это довольно грубое описание, ведь между строк мы можем найти большой пласт “железной” начинки и охапку технологий и алгоритмов, которые призваны решать проблемы коммутации, фильтрации и маршрутизации.
Историческая справка
И вот дальше есть две интересных вещи, первая - наименование "switch", устройство получило по маркетинговым соображениям, а не по причине нововведений, по сравнению с многопортовыми мостами (multiport bridge).
Утверждается, что первый коммерческий коммутатор запустила компания Kalpana, который назывался "EtherSwitch". Основывался он на разработках DEC (DIGITAL EQUIPMENT CORPORATION) и свободно используемом патенте. А поглядеть на коммутатор прошлого, можно тут.
Выдержка из статьи за 2000 г. "До этого (до выпуска 7 ports etherswitch) мосты с технологией коммутации store-and-forward - умирали от роста популярности маршрутизации. Почему EtherSwitch, а не EtherBridge? По двум причинам: Во-первых, "бриджинг" был плохим словом в отрасли, которого избегал любой хороший маркетолог. Во-вторых, продукт Kalpana не соответствовал спецификациям IEEE для моста, поэтому вместо борьбы компания перешла на другое направление."
Есть еще одна точка зрения, с которой я столкнулся на Quora, пока искал исторические корни коммутаторов.
Если коротко, она заключается в том, что первые коммерческие коммутаторы были разработаны не Kalpana, а Alantec и установлены в Verity в 1987 г.
Но если покопать, Alantec, судя по всему, производила свои коммутаторы не на ASIC, а на Intel процессорах. И человек, который утверждал, что версия с Калпаной неверна, так и не ответил на запрос. Поэтому, на данный момент, версия с Alantec несостоятельна.
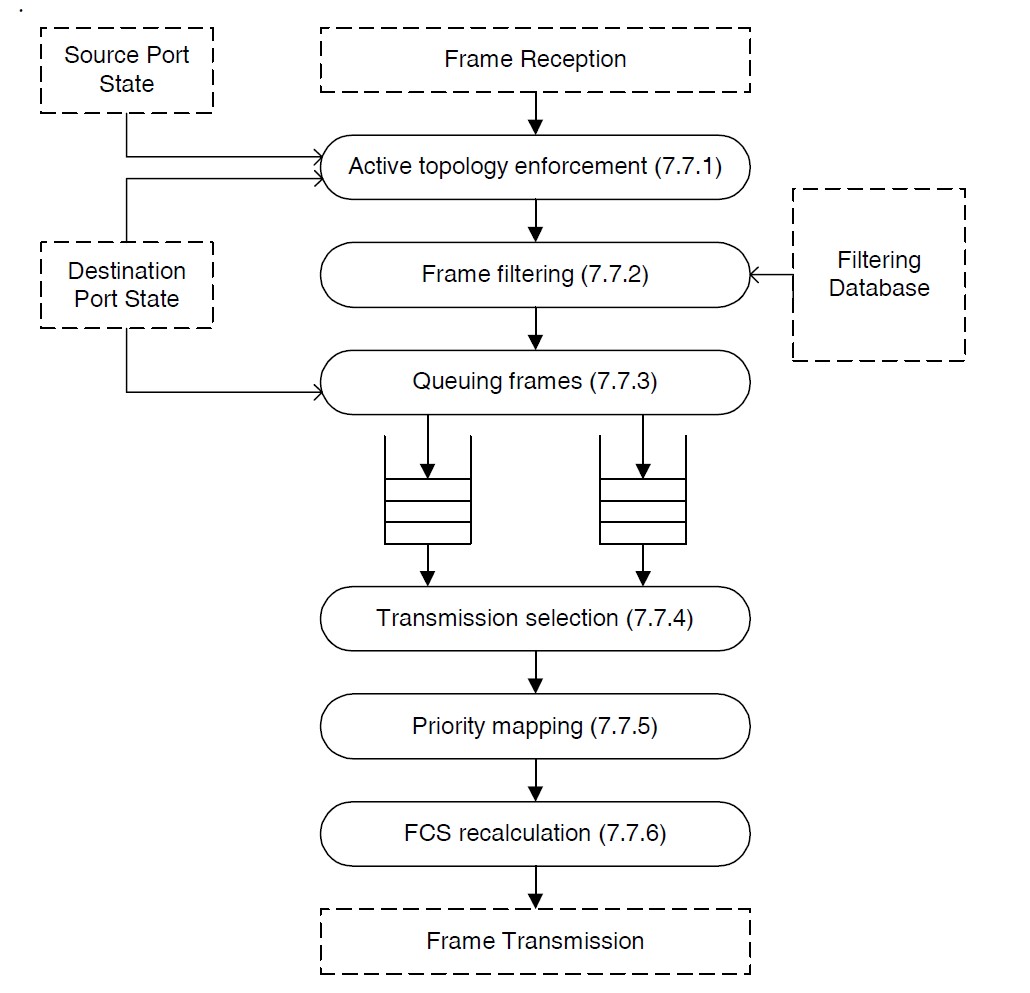
А теперь немного информации из стандартов. Коммутатор, вопреки всяким нетакадам и олиферам, занимается ретрансляцией кадров п.6, процесс ретрансляции можно разделить на три составляющие:
- forwarding - процесс пересылки, обрабатывает принятые кадры, которые должны быть ретранслированы на другие порты моста (коммутатора), фильтруя их на основе информации, содержащейся в MAC-таблице (7.9).
Предположу, что это то, что в большинстве учебных материалов представляется как общий смысл работы коммутатора, ограничиваясь только этим куском.
Далее идут не менее важные части самого процесса пересылки:
- learning - наблюдает за исходными адресами кадров, полученных на каждом порту, обновляет MAC-таблицы (7.9).
- filtering - база данных фильтрации (filtering database) содержащая информацию о фильтрации и поддерживает запросы Процесса пересылки относительно того, могут ли кадры с заданными значениями поля MAC-адреса назначения быть перенаправлены на указанный порт.
А теперь, попробуем восстановить процесс работы с пакетом по порядку.
Сразу стоит уточнить разницу между кадром и пакетом на канальном уровне. Думаю, вы встречали такое, что в разных источниках (да и среди коллег, я уверен) ethernet-фрейм зовут то фреймом, то пакетом. Хотя всем нам известно, что “пакет” - это термин уровнял L3, а “фрейм” - термин уровня L2 все той же OSI. Под спойлером мои небольшие изыскания на эту тему.
Разница между пакетом и кадром на канальном уровне.
Копая стандарт 1985 года, я осознал, что там рассматривается 10base5, а 10base2 был только в рассмотрении.
10. Baseband Medium Specifications, Type lOBASE2 The elaboration of a limited distance, 10 Mb/s, low cost LAN specification is under active consideration by the CSMMCD standard committee.
Начиная с 2005 я нашел определение data-frame , а в ревизии от 2018 года уже и MAC-frame, ниже то, как их определяет стандарт:
1.4.220 data frame: Use of this term is restricted to Clause 9, 27 and 41 (See: MAC Frame).
(9, 27 и 41 это 10, 100 и 1000 мбит соответственно) до mac frame это было как data-frame. (в самом древнем стандарте)
1.4.315 MAC frame: Consists of the Destination Address, Source Address, Length/Type field, MAC Client Data, Pad (if required), and Frame Check Sequence.
1.4.373 packet: Consists of a MAC frame as defined previously, preceded by the Preamble and the Start Frame Delimiter, encoded, as appropriate, for the Physical Layer (PHY) type.
Вот в этом описании, я думаю, кроется истина
9.5.5 Data handling The repeater unit, when presented a packet at any of its ports, shall pass the data frame of said packet intact and without modification, subtraction, or addition to all other ports connected with the repeater unit. The only exceptions to this rule are when contention exists among any of the ports or when the receive port is partitioned as defined in 9.6.6. Between unpartitioned ports, the rules for collision handling (9.5.6) take precedence.
Предположу, что логика не совсем в том, что в какой-то момент преамбула стала посылаться как-то иначе. Просто в момент существования 10base5 об этом не думали, работало и так. А когда делали 10base-t, родили идею, которая заключалась в том, чтобы переопределить фрейм как data-frame, а data-frame + преамбула+sfd в "пакет", служебным заголовком которого является преамбула+SFD (который можно вертеть как хочешь, не важно что с ним произойдет), а data(mac)-frame будет целехонек.
Но если рассматривать опрос с фундаментальной терминологии, дело обстоит так: Кадр - это все, что попало в окно приема, от первого до последнего бита.
Пакет - это осмысленный кусок данных с разделением на служебный заголовок и полезные данные.
В нынешнем ethernet оно поименовано наоборот, вот и получается как в том аенегдоте, что вилька и тарелька пишутся без мягкого знака, а сол и фасол - с мягким. Это невозможно понять и нужно запомнить
После того, как пакет пришел на интрефейс, происходит анализ битовой последовательности (отметается преамбула) затем, в зависимости от сконфигурированного метода коммутации, есть несколько вариантов. На входе пакет обрабатывается одним из трех (четырех) режимов коммутации:
- Store and forward - Обрабатывает пакет целиком. Проверяет FCS. Учит SMAC. Надёжнее, ибо определяет битые фреймы.
- Cut-through - Смотрит только на DMAC. Моден в Infiniband и остальном HPC ибо уменьшает задержки. Требует ручного заполнения таблицы коммутации. Есть его подвид:
- Fragment-free - обязывает коммутатор проверять первые 64 байта кадра, отсылка к минимальному размеру кадра, когда коллизия может быть обнаружена. Используется только в доменах где возможны коллизии, посему не актуален в современных сетях.
По умолчанию используется store-and-forward. Пока происходят манипуляции с заголовком, остаток кадра (полезная нагрузка) попадает в один из буферов (ingress queues), после этого, коммутатор должен узнать, куда переслать кадр (проанализировать его на предмет соответствия политикам фильтрации), нужно ли это делать и как.
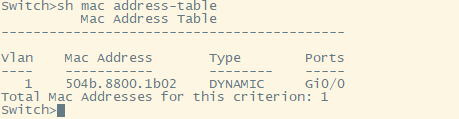
После анализа SMAC коммутатор пополняет свою MAC-таблицу, если таковой отсутствует. Размеры таблиц фиксированы и на разных устройствах они отличаются.
Основная проблема, которая нас подстерегает - переполнение MAC-таблицы.
Для решения проблемы переполнения в нее заносится временная метка (timestamp), когда был выучен MAC-адрес, которая явно не отображается.
Каждый раз, когда коммутатор обнаруживает трафик с MAC-адреса, который находится в его таблице коммутации, он обновляет временную метку этого MAC-адреса. Таймер на коммутаторе периодически проверяет метку времени, и если MAC-адрес узла старше установленного значения, коммутатор удаляет этот MAC-адрес из таблицы коммутации.
Процесс старения (aging) гарантирует, что коммутатор отслеживает только активные MAC-адреса в сети и что он способен очистить из таблицы коммутации MAC-адреса, которые больше не доступны.
Выглядит она следующим образом:
А теперь немного откровений, коммутатор обрабатывает все кадры всегда однотипно и старается передать копию кадра на все порты, за исключением некоторых.
Иными словами, коммутатор не форвардит кадры в соответствии с MAC-таблицей, а MAC-таблица (и другие таблицы) существуют для того, чтобы коммутатор понял, куда нефорвардить пакеты.
Использование терминов уровней OSI
Хабы - устаревшее оборудование (морально и технически). Им на смену пришли Мосты (Bridges), устройства, которые научились делить один домен коллизий на несколько самостоятельных.
Сейчас я, на фоне прочитанного и просмотренного, попробую подкинуть вам идею для размышлений, а именно: какой смысл использования уровней OSI, учитывая стандарт ISO/IEC 7498-1-1994 для L2 Мостов/Коммутаторов?
Тот самый момент, когда на CCNA (и большинстве другх ресурсов) говорят: "коммутатор работает на L2 уровне, маршрутизатор на L3" (MLS пока не трогаем) Для начала определимся что есть что:
Физический уровень (Physical layer) он же L1, подробней в п. 7.7 7498-1-1994. Коротко: занимается передачей потока битов. Тут понятно.
Канальный уровень (Data-link layer), он же L2, подробней в п. 7.6 7498-1-1994. Коротко: предназначен для передачи данных узлам, находящимся в том же сегменте локальной сети. Иными словами, создает канал поверх физической среды.
Сетевой уровень (Network layer), он же L3, подробней в п.7.5 7498-1-1994. Коротко: предназначен для определения пути передачи данных.
Проще всего проследить data-link layer на примере оригинального Ethernet. Когда узел-отправитель пошлет кадр узлу-получателю в общей сети, примет его только узел-получатель, к остальным кадр так же дойдет, но все просто сделают вид, что ничего не видели.
Изначально мост соединял два сегмента сети с одинаковой средой передачи и назывался transparent bridge - это означает, что для хостов, подключенных в мост, этот самый мост прозрачен, хосты ничего о нем не знают. Немного позже появились multiport transparent bridge. Именно в режиме multiport transparent bridge работает современный коммутатор.
В стандарте IEEE 802.1d смотрим, какие функции выполняет мост:
- ретрянсляцию (relay) и фильтрацию (filtering)
- поддержание актуальной информации в FDB (Filtering Database) для принятия ретрансляционных решение и решений фильтрации
- управление вышеизложенным
Так же пора упомянуть термин full-duplex - режим работы возможен только при существовании независимых каналов обмена данными для каждого направления. Естественно, необходимо, чтобы МАС-узлы взаимодействующих устройств поддерживали этот специальный режим. В случае, когда только один узел будет поддерживать полнодуплексный режим, второй узел будет постоянно фиксировать коллизии и приостанавливать свою работу, в то время как другой узел будет продолжать передавать данные, которые никто в этот момент не принимает.
В теории CCNA про работу коммутатора объясняли следующее: коммутатор L2 коммутируеут кадры с помощью стаблицы пересылки (forwarding database, она же таблица MAC-адресов).*
Но если продолжить изучать стандарт, то мы наткнемся на п.5.3.2.3, где говорится, что ретрансляция (relaying) это N+1 layer, а еще и картинка интересная до кучи.
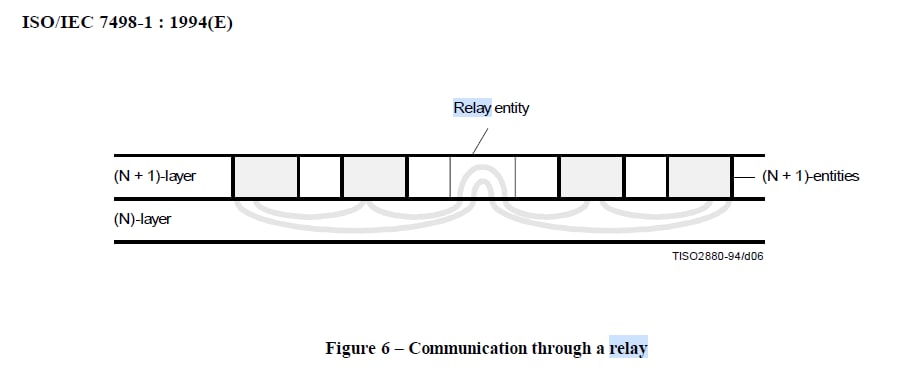
В том же стандарте п. 7.5.4.1.2, описаны функции сетевого уровня (network layer) и одной из них является routing and relaying. Т.е relaying - прямая задача L3.
Итог исторического экскурса, доказательства хоть и косвенные, но называемый в народе L2-коммутатор таки осуществляет L3 функции, но в своем канальном сегменте.
Коммутатор будет L2 только со стороны хоста, который этот коммутатор вообще не ощущает и общается с остальными как в общей сети. В остальном же современный коммутатор решает задачи L3. Когда появляется процесс перекладывания из одной общей среды (домена коллизий) в другой - это relaying, а значит задача L3.
Иными словами, раньше домен коллизий и домен широковещательный совпадали, и Ethernet отлично укладывался в модель OSI, после появления мостов, понятия стали отдельными сущностями, но для хоста это все тот же transparent bridge.
Коммутатор достаточно успешно эмулирует общую среду для всех устройств и от конечного узла сложно определить, что вы подключены именно к коммутатору. По сути, буквы L2,L3 и т.п имеют мало смысла и использовать их стоит только ради соблюдения жаргонных формальностей на собеседованиях.
Основной посыл тут в чем - нельзя пренебрегать стандартами и иногда заглядывать под существующие абстракции, чтобы лучше разобраться в происходящем.
Тут я должен остановить на неоднородности определения термина - MAC-таблица. У нее, как повелось, несколько названий, которые вам, я уверен, встречались. CAM-таблица, таблица пересылки, MAC-таблица.
Но мы тут собрались придерживаться стандартов, а в стандарте 802.1D MAC-таблица есть ни что иное как Filtering Database (FDB).
И, до кучи, мы имеем (кроме FDB) различного рода “таблицы”, которые так же влияют на принятие решения (STP, QoS, ACL и т.п). Отсюда можно вывести список фильтров (уверен, что неполный) которые коммутатор учитывает при принятии решения о ретрансляции:
- Никакой кадр никогда не отправляется обратно в порт, с которого пришел
- Если MAC-destination есть в FDB, то этот кадр не отправляется на все порты, а отправляется только туда, где расположен MAC-destination.
- Никогда и никакие кадры не отправляются в сторону портов, которые заблокированы STP
- Никогда и никакие кадры не отправляются в ту же самую порт-группу из под которой был получен кадр.(несколько портов в один с помощью технологии агрегации каналов)
- Если нет принадлежности к мультикаст-группе, копия мультикаст-кадра в этот порт не посылается.
- ACL
- QoS ACL
Все эти действия происходят одновременно, но на разных частях аппаратной начинки коммутатора.
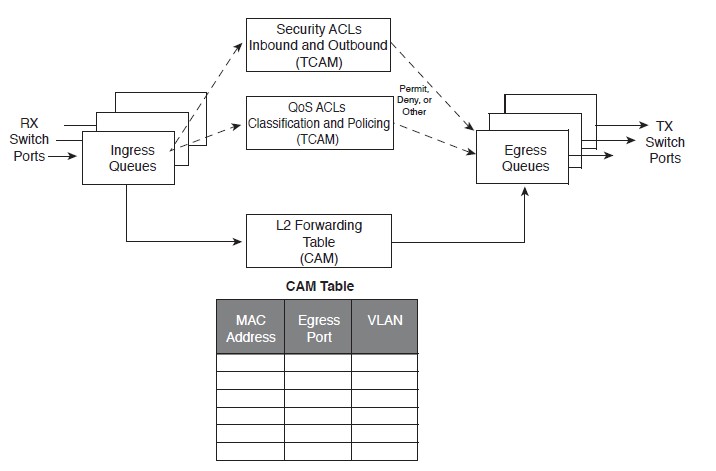
На рисунке можно увидеть два термина, CAM и TCAM, подробнее о них ниже.
Коротко, в CAM и TCAM хранятся значения в виде бинырных ключей (иногда в виде хешей, иногда напрямую), к которым коммутатор обращается каждый раз, когда ему нужно принять решение, что делать с кадром.
Чтобы понять, куда пакет посылать не надо, коммутатор обращается к CAM/TCAM, получает, за один лукап адрес ячейки памяти, в которой лежит нужное значение, в нашем случае DMAC (в CAM/TCAM могут находится разные значения), далее (пройдя при этом все возможные фильтры) копия кадра будет отправлена только в тот порт, за которым обнаружен узел-получатель. Такой трафик называется known unicast.
Далее идет BUM-трафик (Broadcast, unknown-unicast and multicast traffic), когда получатель трафика точне не известен.
Если коммутатор не обнаруживает MAC-адрес назначения, то копия такого кадра, прошедшего цепочку некоторых фильтров (о них дальше), отправляется на все порты коммутатора, кроме того, откуда пришел - это называется unknown unicast flooding.
Подобный кадр получат все хосты в одном широковещательном домене. Который ограничен устройством, работающим с маршрутизацией, либо виртуальными широковещательными доменами (VLAN).
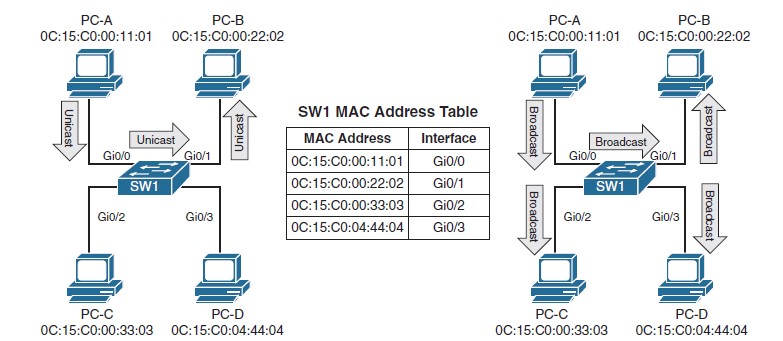
После всех манипуляций, кадр попадает в исходящий буфер (egress queues).
В современных коммутаторах все это делают аппаратные ASIC/NP/FPGA в составе фабрик коммутации при содействии CAM/TCAM.
Далее, я задался вопросом объяснить себе, что лежит в основе процесса пересылки пакетов. Что происходит внутри сетевых коробок?
Сейчас я точно не готов вдаваться в подробности этой всеобъемлющей темы, поэтому обойдемся описанием процесса и термином фабрики коммутации.
Изначально, коммутаторы работали через обущую шину, все всех слышат, коллизии и вот это все. Затем сетевая индустрия обратилась к телефонным станциям той эпохи, перед которыми стояла точно такая же задача коммутации цепей TDM, и скопировала теорию коммутационной матрицы, но разработала ее в кремниевой форме. Основная цель - переключить любой вход на любой выход.
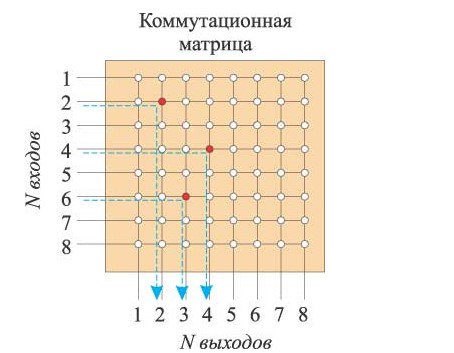
Это всего лишь базовое представление архитектуры. В реальности все куда сложнее. Нужен контроллер, который будет следить за возможными коллизиями (А они будут), нужны буферы (Ingress/Egress), которые будут собирать некоторое количество кадров, оптимизируя работу матрицы. Коммутационные матрицы бывают блокирующие и неблокирующие и т.п интересные вещи.
А теперь коротко, что происходит с пакетом, прилетевшим на порт коммутатора, построенного на основе коммутационной матрицы.
- пакет прилетает в виде вольтов по проводу, декодируется во входной буфер интерфейса, интерфейс дергает фабрику «забирай у меня по известному тебе адресу очередной пакет»
- фабрика по известному ей алгоритму обходит интерфейсы и забирает поштучно пакеты, копируя их к себе в буфер
- фабрика просчитывает список выходных интерфейсов (составляет список, куда отправлять не надо, и вычитает его из списка всех интерфейсов), на выходной буфер каждого из них отправляет копию рабочего кадра из своего буфера
- каждый выходной интерфейс отправляет кадр в среду и стирает его из буфера прр успешной передаче
Что такое фабрики коммутации(коммутационные матрицы), различные виды чипов, как оно устроено внутри и т.д, я разбирать в цикле не буду, но рекомендую ознакомиться самим, сильно добавит понимание происходящего.
Я подобрал несколько источников и предлагаю вам с ними ознакомиться.
Источники:
- отрывок из статьи Марата про фабрики коммутации. (настоятельно рекомендую осилить всю книгу)
- статья в Компьютер Пресс
- Книга Architecture of Network Systems, которую я так же принялся изучать
- В ближайшем будущем, ожидаем курс по архитектуре сетевых устройств, от Алексея Гусева (aka fantas1st0)
Вот вам внутренности Cisco Cat. 2960, который я на днях воскресил на работе, под лабораторные нужды.



Под спойлером я постарался интерпретировать стандарт 802.1D, в котором есть понятие Ретрансляция (Relay), что может натолкнуть на пару интересных мыслей, касаемо терминологии уровней OSI и устройств, к ним относящихся, в контексте L2.
L3 Switching [key-topic]
Перейдем к L3 коммутации, есть две основные методологии:
- Пересылка на устройство в той же подсети
- Пересылка на устройство в другой подсети
Local Network Forwarding
Процедура взаимодействия устройств в локальной подсети достаточно проста, повторяться не буду, но вот про семейство протоколов ARP упомянуть стоит.
ARP
Чтобы сформировать кадр, необходимо знать MAC-адрес получателя. Вышестоящие уровни не обладают этой информацией, а только адресом L3 (обычно IP-адресом). Получателю свой MAC-адрес известен, следовательно, он и должен его сообщить. По получателю неизвестно, что с ним пытаются связаться. Поэтому отправитель должен предварительно отправить запрос. Это нельзя сделать адресно (нет собственно MAC-адреса), нельзя сделать групповой рассылкой (любой узел может быть получателем — такая группа включала бы все узлы), следовательно, остается широковещательная рассылка запроса.
Протокол разрешения адресов (address resolution protocol, ARP) и предназначен для нахождения MAC-адреса по IP-адресу. Структура пакета представлена ниже.
ARP не единственный в своем роде, их целое семейство:
- Протокол RARP
- Протокол InARP
- Протокол UNARP
- Протокол SLARP
- Протокол DirectedARP
Механизм работы основан на принципе запрос/ответ.
ARP работает в пределах локальной подсети. И не может содержать в таблице записи устрйств из других подсетей, но может содержать адрес next-hop в другие подсети. Для “связи” двух различных подсетей, есть механизм proxy-ARP, о нем ниже.
Формат пакета ARP:

ARP-запрос отправляется на широковещательный MAC-адрес ff:ff:ff:ff:ff:ff.
Инкапсулируется в заголовок L2 уровня (в данном контексте в 802.3 Ethernet) и использует код вложения 0x0806. В теле ARP-запроса поле с неизвестным значением Target MAC Address заполняется нулями.
Поле opcode в заголовке ARP может принимает значение 1 для ARP-запроса и значение 2 для ARP-ответа.
ARP-ответ отправляется на MAC-адрес получателя, отправившего ARP-запрос. В поле Sender MAC Address указывается запрашиваемый MAC-адрес устройства.
При получении ответа ARP клиент считывает MAC-адрес и IP-адрес из ответа и добавляет их в свою таблицу ARP.
ARP-таблица содержит соответствие IP адреса и MAC адреса устройства, которая затем используется для составления заголовка перед отправкой пакета в сеть.

В сложных случаях, для передачи запросов ARP может использоваться один протокол канального уровня, а для связи с искомым узлом — другой. При этом адрес отправителя в кадре-ответе и адрес отправителя в ответе ARP (содержимом кадра) не будут или даже не могут совпадать. Строго говоря, ARP не ограничен MAC- и IP-адресами, но применяется в основном для них.
При включении в сеть, некоторые устройства и ОС посылают так называемые анонсы ARP (ARP announcement) или приветственные ARP (gratuitous ARP), ответы ARP самому себе, но посланные на широковещательный адрес. Таким образом присутствовавшие в сети устройства могут узнать о новом устройстве в сети.
Источник: статьи, которые я использовал при подготовке статьи: https://www.atraining.ru/arp-inarp-rarp-proxy-gratuitous-dai-sticky-and-more/ https://cbs.ru/lib/technical-articles/10821/ https://cbs.ru/lib/technical-articles/arp-pt-2/
Packet routing
Любой пакет должен быть смаршрутизирован, когда два узла находятся в разных сетях. Основным протоколом для решения этой задачи, является IP (ipv4/ipv6).
Существуют различные канальные среды, по которым можно гонять IP.
- Ethernet 802.3
- догическая точка-точка (туннели и последовательные порты)
- NBMA (DMVPN)
- логическая точка-многоточка (WiFi)
Чтобы отправить пакет в другую сеть, узлу необходимо заглянуть в таблицу маршрутизации и найти там адрес следующего перехода (next-hop) используя инструкцию Longest match (наибольшее вовпадение), маршруты могут там появиться несколькми способами:
- статический маршрут (static route)
- маршрут по умолчанию (default gateway)
- динамические протоколы маршрутизации
Первые маршрутизаторы Cisco принимали пакет, отрезали L2 заголовок и проверяли, существует ли маршрут для DIP (destination IP), если существует, то приклеивался новый L2 заголовок и пакет продолжал свой путь, если нет, пакет отбрасывался (drop).
Сейчас, в силу технологий, процесс выглядит проще, никаких откусить/приклеить больше нет, происходит процесс переписывания (rewrite) заголовков. По причине простоты процесса, маршрутизатор/MLS может перемалывать огромное кол-во пакетов с минимальной задержкой, аппаратно.
Путь пакета в L3, похож на путь пакета в L2.
Виды MLS
Route caching: MLS первого поколения, похожи на аналог fast switching. Есть RP (Route processor), обрабатывающий первый пакет в потоке, чтобы определить его назначение. SE (Switch engine), слушает первый пакет и результат поиска его назначения и добавляет "короткий путь" в MLS cache. Далее SE работает с последующими пакетами потока без участия процессора, используя аппаратные схемы (например ASIC).
Topology based: Второе поколение MLS, аналог CEF в Cisco. Основан на принципе предварительного формирования кэш-таблицы маршрутизации, без участия трафика. RP анализирует маршрутную информацию из таблицы маршрутизации и записывает в аппаратный чип. Имея на руках заполненную таблицу, SE начинает пропускать пакеты прямо через ASIC, не прибегая к помощи RP. Обращаясь к аппаратной таблице маршрутизации и посредством longest prefix match принимать решение, по какому next-hop пустить пакет.
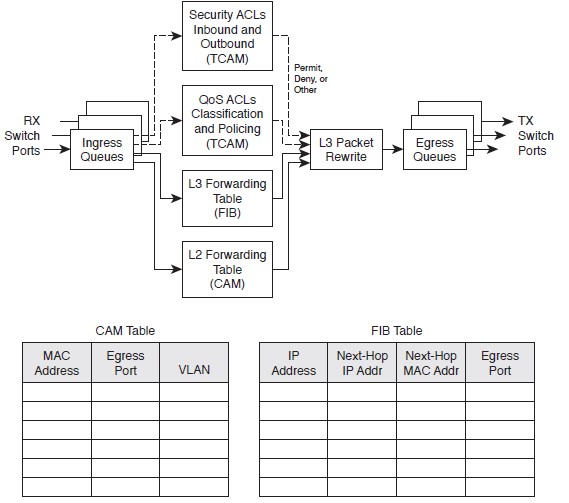
Пакет так же попадает в Ingress queue, но адрес назначения анализируется уже и на уровне MAC и на IP. Решение, куда отправить пакет, будет основываться на двух таблицах, вместо одной.
Таблица пересылки L2: MAC-адрес назначения используется в качестве индекса в памяти CAM/TCAM. Если кадр содержит пакет уровня 3, который необходимо перенаправить из одной подсети в другую, MAC-адрес назначения будет содержать адрес порта уровня 3 на самом коммутаторе. В этом случае результаты FDB, хранящейся в CAM/TCAM используются только для принятия решения о том, что кадр должен быть обработан на уровне 3.
Таблица пересылки L3: Запрашивается таблица FIB с использованием IP-адреса назначения в качестве индекса. Найдено самое длинное совпадение в таблице (как адрес, так и маска), и в результате получен адрес уровня 3 следующего перехода. FIB также содержит MAC-адрес каждого маршрутизатора следующего перехода уровня 2 и порт выходного коммутатора (и идентификатор VLAN), так что дополнительные поиски в таблице не требуются.
Дальше происходит процесс переписывания заголовков (rewrite), о котором я писал выше:
- Изначально, пакет имеет MAC-адрес идентифицирующий конкретный MLS, это позволит ему понять, что пакет предназначается ему, поэтому необходимо вскрыть заголовок IP.
- Для того, чтобы пакет отправился дальше, необходимо знать MAC-адрес назначения другого MLS/Маршрутизатора.
- MLS обратится к FIB и узнает next-hop IP и MAC
- MLS переписывает исходный DMAC
- Уменьшает TTL на единицу
- Пересчитывает FCS L2 и L3 т.к содержимое заголовков поменялось.
- Отправка в Engress queue
Все вышеперечисленные операции происходят аппаратно. Процедура повторяется для каждого next-hop узла.
Одна из ключевых составляющих сетевого взаимодействия - VLAN, рассмотривается в следующем разделе
IPv4/IPv6
TCP/IP стек стал стандартом для индустрии. Система IPv4 подразумевала использование публичных и частных адресов, размером в четыре октета (32 бита) и определяющей маской. С ходом времени, публичные адреса начали истощаться и инженерное сообщество придумало IPv6, уже размером 128 бит и префиксом. Однаком, переобуться на ходу не вышло, уже 2022 год, основные узлы интернета научили IPv6, крупные компании уже могут позволить себе IPv6 only (например Яндекс), но, в подавляющем большинстве, мы все еще живем в реалиях IPv4. Однако процесс идет и это хорошо.
Собственно сам стек протоколов TCP/IP, думаю он вам знаком:
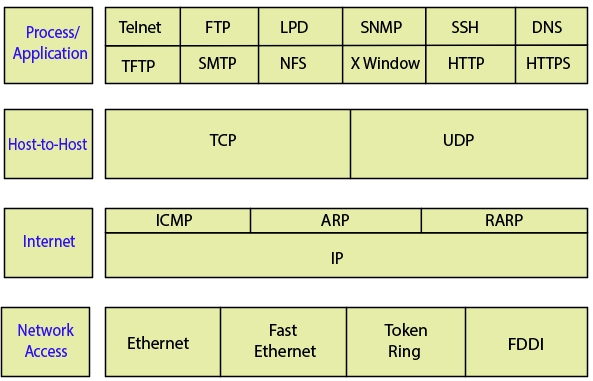
Мы сейчас где-то между Network access и Internet, поэтому продолжим далее про маршрутизацию.
IP предоставляет два фундаментальных сервиса сетевого уровня:
- Логическая адресация
- Маршрутизация
IP-адрес назначается на каждом маршрутизируемом интерфейсе маршрутизатора или MLS.
Любой такой адрес будет считаться connected сетью с административной дистанцией (administrative distance) - 0. Подобные сети не могут быть вытеснены протоколами маршрутизации.
В своб очередь, IPv6 адрес можно добавить несколько на один интерфейс, равносильно secondary в IPv4.
Все адреса сетей хранятся в routing information base (RIB), она же таблица маршрутизации (routing table).
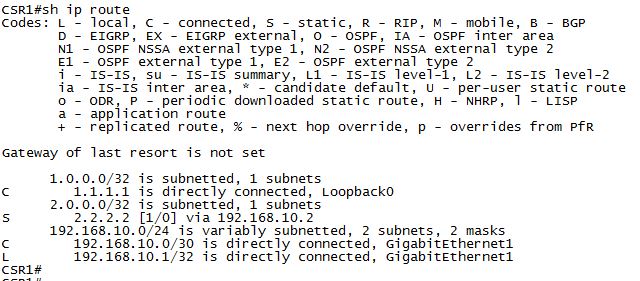
В RIB (Routing Information Base) попадает весь L3 (BGP, OSPF, EIGRP, статика). В RIB происходит процесс выбора наилучшего маршрута. В помощь идут L2 вещи (ARP-таблицы и разные L2 протоколы).
Все это загружается в сущность под названием FIB (Forwarding Information Base) - это некая софтверная абстракция лучших маршрутов и L2 путей до next-hop. Дальше все загружается в TCAM. И уже из нее, за один временной цикл или один(или несколько) lookup-ов, происходит принятие коммутационных решений, на основе входяшей/выходящей информации.
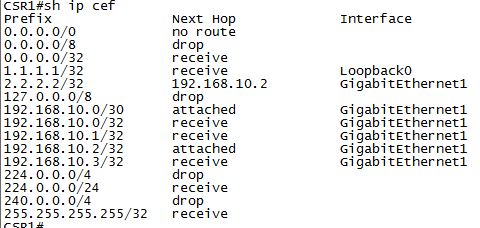
Есть несколько вариантов связать разные сети используя MLS и маршрутизатор:
- маршрутизируемый сабинтерфейс
- SVI (inter VLAN routing)
- маршрутизируемые интерфейс MLS
Подробнее о них и о FIB будет в следующем разделе
Forwarding architectures [key-topic]
Очень объемная тема, которая в OCG описана не очень то понятно. Попробую немного восполнить этот пробел. Для того, чтобы лучше понять тему, важно определить понятия плоскостей в коммутаторах, подробнее о них можно прочитать тут
Forwarding/Data Plane - занимается доставкой трафика и обращением к чипам CAM/TCAM. Иногда эти понятия разделяют, но чаще всего это одно и то же. Операции выполняются на чипах (например ASIC).
Control plane - занимается заполнением различных таблиц, с помощью которых коммутатор определяет судьбу пакета. Операции Control plane выполняются на CPU.
Management plane - не всегда выделяется в отдельную плоскость, можт быть частью control plane, технически, это модуль, который мониторит состояние устройства и его конфигурацию.
Вот теперь переходим к методам коммутации, у Cisco они представлены в трех вариантах:
Process switching - метод, в котором основную роль в коммутации пакетов играет CPU. Процесс ip_input в IOS - основной механизм коммутации на CPU, который занимается обработкой входящих IP-пакетов. Этим занимается Control Plane.
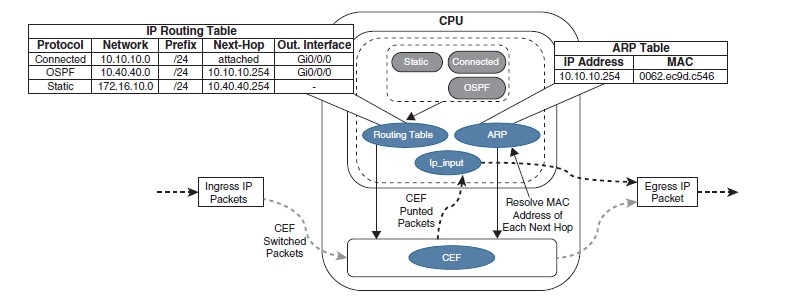
Хорошая картинка из OCG ENCOR, показывающая работу PS, когда пересылка через CEF невозможна.
Процесс ip_input обращается к таблице маршрутизации (RIB) и таблице ARP, чтобы получить IP-адрес next-hop маршрутизатора, исходящий интерфейс и MAC-адрес. Затем он перезаписывает MAC-адрес назначения пакета MAC-адресом маршрутизатора следующего перехода, перезаписывает MAC-адрес источника MAC-адресом исходящего интерфейса уровня 3, уменьшает значение поля IP time-to-live (TTL), пересчитывает контрольную сумму заголовка IP и, наконец, доставляет пакет к next-hop маршрутизатору.
Fast switching - в этом варианте на CPU обрабатывается только первый пакет в потоке, для того, чтобы считать информацию и занести ее в fast cache. После этого, последующие пакеты, в том же потоке, будут проходить через Data Plane.
CEF - проприетарный механизм коммутации. Используется на всех (где есть, так скажем L2+ функционал) платформах Cisco, как работающих на процессоре, так и на ASIC и сетевых процессорах (NP).
В современных коробках CEF включен по умолчанию. Через CPU проходит весь Control/Management Plane, а Data/Forwarding plane занимается CEF. Process switching являются резервным способом, если что-то случится с CEF.
Исключения, которые гарантированно проходят через process switching:
- ARM запрос/ответ
- IP пакеты, требующие ответа маршрутизатора (TTL равен 0, нужно сгенерировать сообщение, превышение MTU, нужна фрагментация и т.п)
- IP широковещательные пакеты, которые нужно передать как одноадресные (DHCP request, функции IP helper-address)
- Обновления протоколов маршрутизации
- CDP
- Необходимость шифрования пакетов
- NAT (есть исключения)
Существуют реализации как программного CEF (software CEF) - когда все операции выполняет процессор и аппаратный CEF (hardware CEF) - когда механизм CEF реализован на аппаратных чипах ASIC, CAM/TCAM, а так же NP.
Подробнее про CEF в следующем разделе
Searching
Коммутаторы Cisco Cat. используют внутреннюю архитектуру Ternary Content Addressable Memory (TCAM) для коммутации, фильтрации и маршрутизации. TCAM память содержит в себе таблицу с бинарными значениями, по которой необходимо провести поиск, чтобы найти необходимую информацию.
Прежде чем перейти к TCAN, разберем самый простой вариант - индексированное чтение. Индексное чтение, по существу, это память, где аргумент поиска (значение на входе) используется напрямую, как ввод адреса памяти. Другими словами, входное значение указывает непосредственно на соответствующую запись в таблице без каких-либо манипуляций с этим значением.
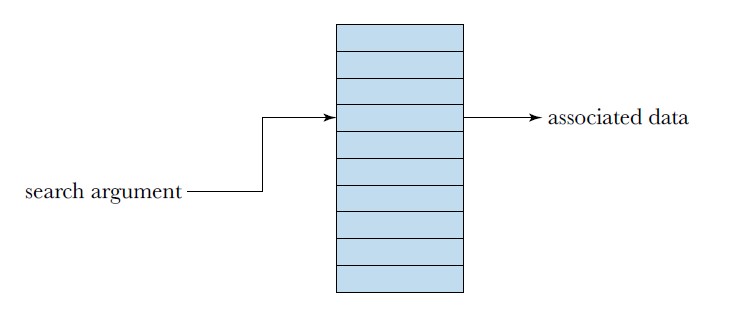
Подобный поиск очень прост и поэтому весьма производителен. Оптимален для точного соответствия.
Операция поиска по значениям необходима для многих действий переадресации (forwarding search).
Типичная задача переадресации - входное значение, которое берется из заголовка пакета, подается в целевую базу данных, для поиска подходящего ключа.
Результат - либо совпадение, либо несовпадение.
совпадение - побочным продуктом операции будет ассоциированное с ключем значение, которое укажет, например, на ячейку памяти RAM, в котором хранится необходимая информация, которая после будет использована для продолжения процедуры пересылки.
несовпадение - будет возращено значение по умолчанию (lookup-type) или специфическое значение базы данных или процесс пересылки обработает несовпадение как-то по своему.
А подобные задачи отлично решает CAM/TCAM.
CAM/TCAM
Еще один вид поиска по таблице, но в отличии от индексной памяти, CAM/TCAM это специализированная память, в которой каждое хранимое значение в таблице сравнивается (compared) с представленным аргументом поиска (ключом) параллельно.
CAM (Content Addressable Memory) - разработана с целью повышения скорости поиска в FDB, для принятия решений коммутации.
Память CAM состоит из массива ячеек (регистров памяти), подключенных к общей шине ввода данных. Ethernet шина и регистры должны вмещать >48 бит (по размеру MAC-адреса)
Для сравнения используются бинарные ключи (0/1).
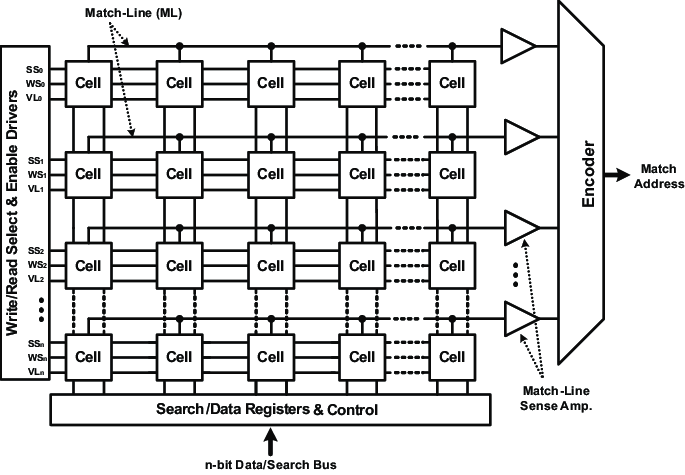
Но CAM нынче мало интересен, которого даже в Catalyst коммутаторах нет, вместо CAM используется TCAM.
TCAM (Ternary Content Addressable Memory) - расширение CAM, используется для более широких задач, в том числе может свободно выполнять роль CAM.
Кроме реализации поиска префиксов, TCAM способна переваривать ACL, QoS и других данных, полученных в результате обработки на верхнем уровне. Все это возможно благодаря архитектуре TCAM и SDM шаблонам, позволяющим “перенастроить” или более гибко распределить мощности TCAM под нужные задачи.
Схема подобна CAM, но TCAM может дать нам три разных результата при выполнении поиска: 0, 1 и X (состояние мне безразлично).
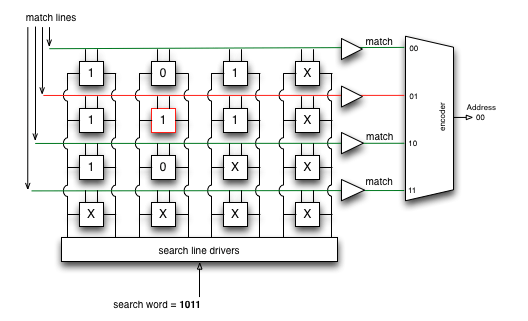
Картинку украл из книги Марата, ссылок на нее тут предостаточно :)
Благодаря этому новому состоянию, TCAM идеально подходит для построения и поиска таблиц для хранения самых длинных совпадений в таблицах IP-маршрутизации.
Механизм работы TCAM проще всего объясняет на примере поиска маршрута, в котором TCAM находит, за один цикл (clock cycle), каждый префикс назначения в FIB, используя принцип Longest prefix matching (LPM).
Перед записью в TCAM, префиксы должны быть отсортированы так, чтобы самый длинный попадал в верхние позиции, тем самым обладал бы самым высоким приоритетом

На рисунке видно, что зелеными марками отмечены подходящие вхождения, но актуальным будет только индекс 2, в соответствии с принципом LPM.
Каждый префикс в FIB (термин из CEF, о котором позже) указывает на заранее подготовленный L2-заголовок таблицы смежности для каждого исходящего интерфейса. Та же FIB хранится именно в TCAM, с которой проще всего работать аппаратно. Маршрутизатор приклеивает заголовок к рассматриваемому пакету и отправляет его через нужный интерфейс.
Структура TCAM состоит из комбинации значения (Value), маски (Mask) и результата (Result).
Значение указывает поля, в которых следует выполнить поиск, например поля IP-адреса и протокола. Маска указывает на поле, которое представляет интерес и которое должно быть запрошено. Результат указывает на действие, которое следует предпринять при совпадении значения и маски. Можно выбрать несколько действий, помимо разрешения или удаления трафика, но возможны такие задачи, как перенаправление потока на QoS policer или уточняющее указание на другую запись в таблице маршрутизации.
В OCG SWITCH есть пример на основе ACL, но приводить его тут будет излишне (и так информации тонна) + я не до конца разобрался как это работает. Поэтому если будет актуально, добавлю отдельной мини-статьей, как соображу что к чему. А пока, оставлю вам на самостоятельное изучение, если будет интерес.
TCAM так же используется для хранения расчетов программного CEF.
Подробнее про чипы памяти: Где сохранить пакет?
Источники: картинки взяты из книги HARDWARE-DEFINED NETWORKING
научные публикации из открытых источников, которые (как и книгу выше) можно найти в ЯД
- Novel Ternary Content-Addressable Memory (TCAM) Design Using Reversible Logic
- Content-Addressable Memory (CAM) Circuits and Architectures: A Tutorial and Survey
- Demonstration of CAM and TCAM using Phase Change Devices
- D-TCAM: A High-Performance Distributed RAM Based TCAM Architecture on FPGAs
- TCAM ARCHITECTURE FOR IP LOOKUP USING PREFIX PROPERTIES
На этом закончим, получилось очень длинно…следующая остановка: CEF и VLAN.
Далее: поговорим наконец о VLAN и CEF. Ну и может еще что добавлю по дороге.
Хочешь обсудить тему?
С вопросами, комментариями и/или замечаниями, приходи в чат или подписывайся на канал.