ENCOR 350-401|Часть 1.2 - VLAN, CEF
CCNP ENCOR 
Приветствую друг!
Совсем немного подумав, я решил продолжать CCNP ENCOR. Да, Cisco ушла и да, надеяться на ее возвращение я не стану. НО, мне все так же интересно двигаться по пути сетевика и так уж вышло, cisco - часть пути. Сегодня все те же старые песни о главном. VLAN, MLS, CEF. Потихоньку движемся в современность.
Не претендую на истину в последней инстанции, весь цикл - приглашение к диалогу. Если я где-то ошибся, сообщи об этом, будет полезно мне и остальным.
VLAN [key topic]
Аксиома: Кадры Ethernet, без посредника в виде протокола сетевого уровня, за пределы широковещательного домена передавать нельзя.
Обычно про VLAN рассказывают в контексте разделения по группам (например отделы с сотрудниками) на широковещательные домены, мы это помним, поэтому зайдем с другой стороны.
Обратимся к Spanning Tree - протокол, придуманный умной тетей Радей, для предотвращения падения сети от внезапной петли в L2 топологии. Работа алгоритма SPI (основа протокола) является построение дерева топологии, основой которого является root бридж, а избыточные линки блокируются.
Один из нюансов такого подхода - неэффективное использование потенциальной пропускной способности всех доступных линков между коробками.
Подобное поведение хорошо продеманстрировано на следующих 4-х картинках.
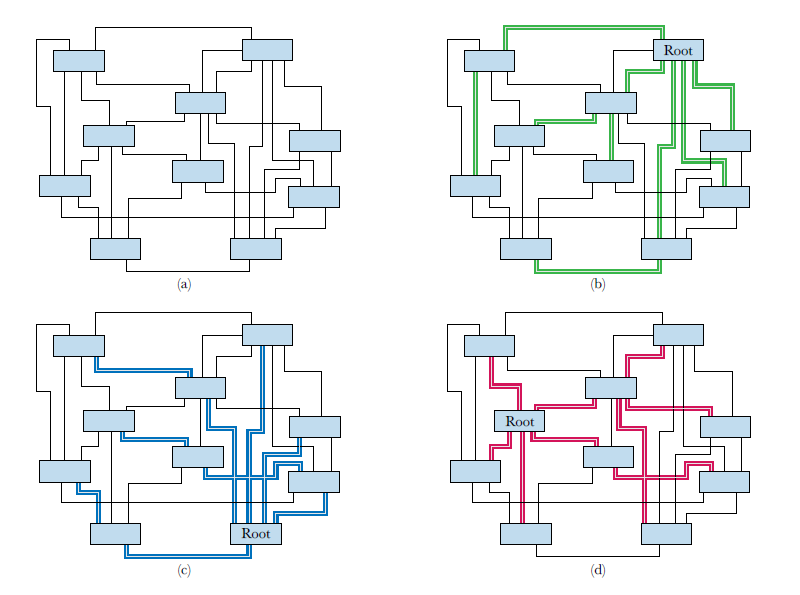 a) комплексная сеть с множеством резервных путей
b, c, d) активный spanning tree протокол с выбранным root в разных частях сети, цветом показаны доступные пути прохождения трафика, все остальное - заблокированные линки
a) комплексная сеть с множеством резервных путей
b, c, d) активный spanning tree протокол с выбранным root в разных частях сети, цветом показаны доступные пути прохождения трафика, все остальное - заблокированные линки
Понятно, что сейчас принято максимально уходить от L2 в корпоративных сетях и выше и оставлять его, максимум, на уровне доступа, при использовании классической 3-х уровневой модели.
Лирическое. Пока мы находимся в рамках учебных материалов, а мой опыт предельно мал, чтобы рассказать что-то интересное из современных практик, я прошу меня простить.
Одним из способова решения озвученной проблемы - виртуальные сети. С помощью виртуальных сетей мы можем назначить root бридж для каждой из VLAN и использовать резервные линки более эффективно. На картинке можно увидеть, что некоторые пути трафика (обозначенные зеленым, красным и синим) иногда проходят через одни и те же свичи.
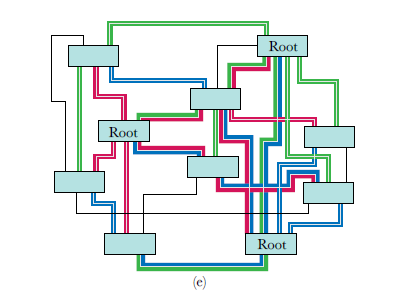
Для изоляции трафика бриджей был изобретен и стандартизирован IEEE как стандарт 802.1Q он же VLAN tag.
Почему мы начали со spanning tree? При создании VLAN вы, фактически, создаете виртуальный объект или, если удобно, виртуальный коммутатор, внутри физической коробки. Данный виртуальный объект пересылки, будем его так называть, будет иметь свою таблицей пересылки и прочие атрибуты, своейственные его физическому родителю, включая и процесc STP. В этом и заключается концепция VLAN - разделение на виртуальные широковещательные домены.
Запуск нескольких экземпляров связующего дерева в нескольких VLAN известен как протокол множественного связующего дерева (MSTP) и стандартизирован IEEE 802.1s. Протокол MSTP позволяет нескольким VLAN быть связанными с экземпляром протокола Rapid Spanning Tree и для работы нескольких экземпляров протокола Rapid Spanning Tree. в одной физической сети Ethernet, то и продемонстрировано на картинке выше.
VLAN tag очень простая сущность. Он состоит, в основном, из некоторой информации о приоритете и значения VLAN ID.
Каждый экземпляр объекта пересылки имеет свою FDB и работает независимо от других экземпляров. Пакеты, связанные с одним экземпляром, никогда не могут быть перенаправлены в виртуальную сеть другого экземпляра, без вмешательства посредника.
Выглядит просто, но не совсем. Проблема, как всегда, кроется в истории. Создатели Ethernet понятия не имели о каком-то там “VLAN”. Поэтому в заголовке Ethernet изначально нет ничего, что на него могло бы указывать.
В идеале, VLAN ID должен стоять в начале заголовка Ethernet т.к VLAN ID фактически меняет способ интерпретации ethernet кадра. В сухом остатке, исторически стандарт ethernet требует, чтобы первые байты пакета Ethernet всегда были 14-байтовым заголовком Ethernet, и по соображениям обратной совместимости это вряд ли когда-то изменится.
Интересно, что слово “тег” было выбрано в угоду маркетингу, чтобы представить люду VLAN технологию как инкрементный апдейт Ethernet, в заголовок которого интегрируется нечто, а не напрямую добавляется к нему. Иными словами, наш тег вполне подходит под критерии полноценного заголовка. Он передает полезную информацию и указывает тип заголовка или информации, которая следует за ним.
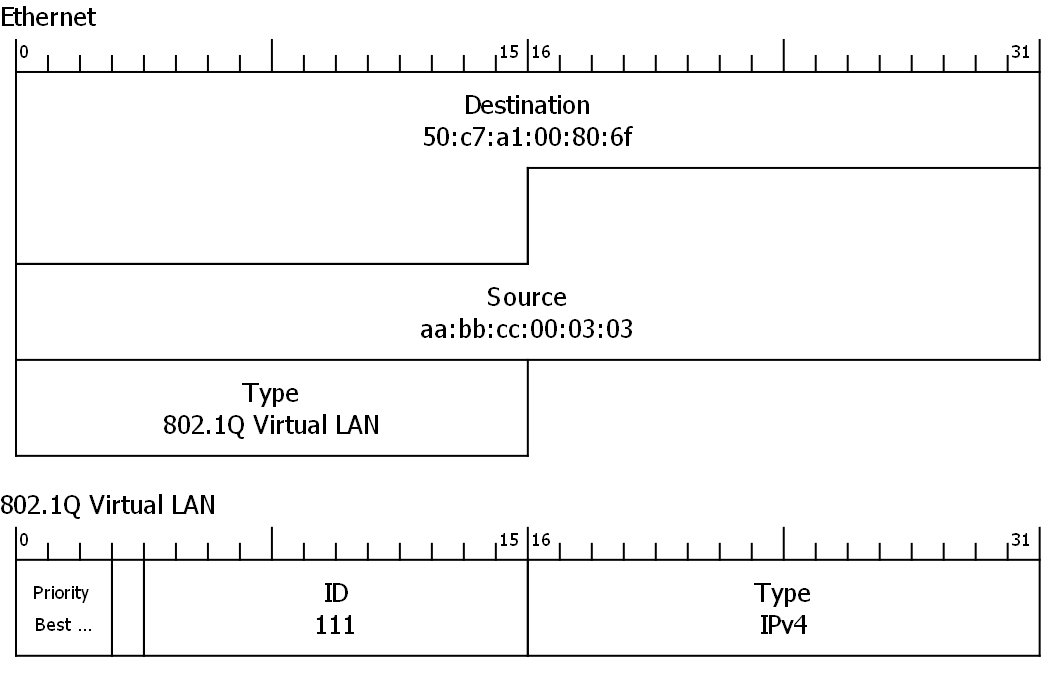
В данный момент имеем следующую схему включения тега в заголовок ethernet II:
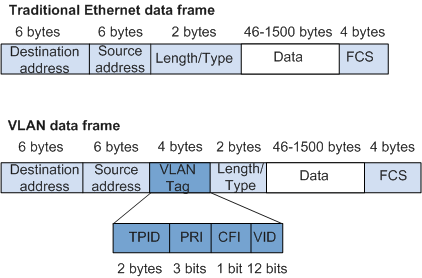
Пара MAC-адресов, за которыми следует субзаголовок 802.1q, который идентифицирует тег VLAN (идентификатор протокола тега или TPID), затем значения приоритета и идентификатора VLAN (информация об управлении тегом, или TCI), за которым следует значение ethertype (jчасть заголовка ethernet, смещенная на длину субзаголовка 802.1q), которое идентифицирует то, что следует за тегом VLAN.
Добавление 4-байтового тега VLAN к пакету не увеличивает минимальную длину пакета Ethernet в 64 байта, но увеличивает максимальную с 1518 байт до 1522 байт.
При подобной манипуляции (запихать в ethernet заголовок тэг) чек-сумма пересчитывается
Несколько других усовершенствований Ethernet увеличили стандартную максимальную длину до 2K байт, а длина нестандартных, так называемых jumbo пакетов, достигает 9K байт и выше. Иными словами, современные железки нормально относятся к такому явлению.
Посмотрим на VLAN заголовок подробнее:
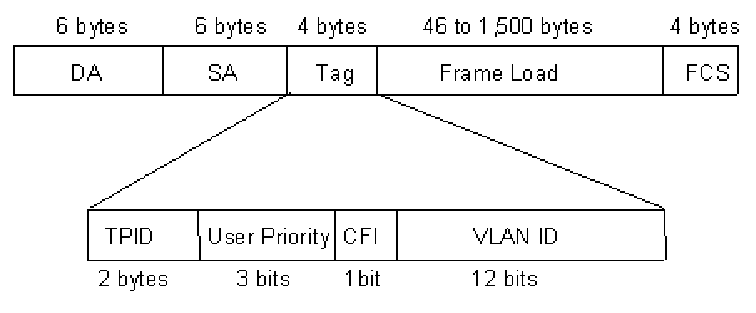
- Поле TPID – Tag Protocol ID – два байта, идентифицирующие тип доп.заголовка – всегда
0x8100. - Поле PCP – Priority Code Point – три бита, он же 802.1p. Эти три бита также часто называются CoS – Class of Service.
- Поле CFI – Canonical Format Indicator – 1-битовый флаг, показывающий формат MAC-адресов. Исторический рудимент и всегда = 0. Если равен 1, это означает, что в теле пакета имеется что-то, отличное от обычного MAC-адреса.
- Поле VID – Virtual LAN ID – 12 бит, содержащих наконец-то главное – номер VLAN’а. Это не 4096 (т.е. 2^12), потому что два значения зарезервированы: значение VLAN ID
0x000означает, что пакету не присвоено значение VLAN ID, в то время как значение VLAN ID0xfffвсегда интерпретируется как недопустимый идентификатор VLAN.
А вот так это выглядит в “живом” трафике (дальнейшие заголовки пока излишни):
Концепция default vlan [key topic]
Каждый физический или логический интерфейс может быть сконфигурирован с идентификатором VLAN по умолчанию. Идея заключается в том, что, если пакет получен без идентификатора VLAN (он все еще может иметь заголовок только с приоритетом 802.1p), ему назначается VLAN по умолчанию.
У вендоров он называется по разному. У Cisco - native vlan, у Huawei - PVID (port default VLAN ID) и т.п.
Все кадры, обрабатываемые в коммутаторе, содержат теги VLAN. Когда коммутатор получает кадр без тегов, он добавляет к кадру тег VLAN в соответствии с VLAN по умолчанию интерфейса, на котором получен кадр. Default VLAN используется в следующих сценариях:
- Когда интерфейс получает кадр без тегов, интерфейс добавляет к кадру тег с Default VLAN и отправляет кадр коммутатору для обработки. Когда интерфейс получает помеченный кадр, тег не добавляется.
- Когда интерфейс отправляет кадр, в котором идентификатор VLAN совпадает с Default VLAN, коммутатор удаляет тег из кадра перед отправкой его из интерфейса.
Каждый интерфейс имеет VLAN по умолчанию. VLAN ID по умолчанию для всех интерфейсов равен VLAN 1.
- Default VLAN на интерфейсе Access - это VLAN, разрешенный на этом интерфейсе. Изменение разрешенных VLAN также приведет к изменению Default VLAN.
- Trunk интерфейсы и Hybrid интерфейсы допускают несколько VLAN, но имеют только один Default VLAN. Изменение разрешенных VLAN не приведет к изменению Default VLAN.
И немного вспомним типы интерфейсов:
- Access
- Trunk
- Hybrid (у cisco это называется Voice VLAN, во всяком случае очень похоже)
Access [key topic]
Конечное устройство о VLAN (в классической топологии), ничего не знает. Для более эффективного разделения сегментов сети можно назначить порт в режим Access, после чего, приходящий, на этот порт, трафик, будет назначен соответствующий VLAN. Тег 802.1Q не включается в кадр (принятый или отправленный) на access интерфейсах.
На порт в режиме Access можно назначить только один VLAN.
Trunk [key topic]
На порт в режиме trunk может быть назначено несколько VLAN. Используется в случае необходимости связи с другим:
-
если trunk порт пытается отправить кадр, он добавляет к кадру метку, в которой пишет некоторое число (например, номер влана). Причем 802.1q заголовок добавляется к кадру в момент отправки с интерфейса.
-
если trunk порт принимает кадр с меткой на интерфейсе, он читает это число, определяет по этому чтслу номер влана (это легко, если отправитель туда его и написал), а затем стирает метку, после чего кадр отправляется на коммутацию.
Отдельно стоит упомянуть про реализацию trunk на маршрутизаторах. Решается эта задача с помощью саб-интерфейсов, в учебниках еще зовется Router on a Stick (Роутер на палке). Используется в случае, когда мы хотим связать коммутатор и маршрутизатор по L2. Есть нюанс, в транке передается несколько VLAN, но на маршрутизаторе каждому VLAN необходимо создать отдельный виртуальный саб-интерфейс, каждый из которых будет дочерним для одного физического родителя.
Настройка IP производится на логических саб-интерфейсах.
Hybrid
На этом типа интерфейса так же возможна работа меток 802.1q, но untagget (без тега) VLAN на этом интерфейсе может быть не один (как в access), а столько, сколько нужно. Данный тип порта – настройка по-умолчанию на коммутаторах Huawei.
Частый кейс по настройке hybrid интерфейса - работа с VOIP-трубками и QinQ.
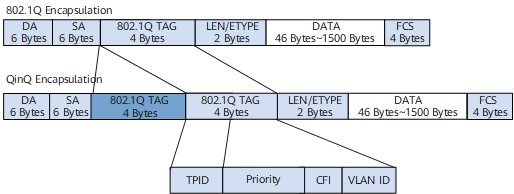
Немного про QinQ
QinQ (802.1q in 802.1q) - может добавить дополнительный тег 802.1Q к помеченному фрейму. QinQ поддерживает до 4094 x 4094 VLAN. Внешний тег часто называется общедоступным (public) тегом и идентифицирует идентификатор VLAN общедоступной сети, в то время как внутренний (private) тег часто называется частным тегом и идентифицирует идентификатор VLAN частной сети.
Прежде чем пакеты из нескольких VLAN, предоставляемых поставщиком услуг (public), попадут в пользовательскую сеть (private), внешние теги VLAN должны быть удалены. Здесь нельзя использовать trunk интерфейс, поскольку trunk пропускает только немеченые пакеты из VLAN интерфейса по умолчанию.
Отсюда мы имеем пакет с двойной меткой, который выглядит так:
Inter-VLAN routing [key topic]
Коротко резюмируем - сеть L2 работает в рамках одного широковещательного домена. С технологией VLAN это могут быть десятки виртуальных широковещательных доменов, изолированных друг от друга.
Для передачи пакетов между VLAN необходимо использовать L3 устройство. Традиционно это была функция маршрутизатора. Маршрутизатор должен иметь физическое или логическое соединение с каждой VLAN, чтобы он мог пересылать пакеты между ними. Эта функция известна как - Inter-VLAN routing.
Я немного упомянул про Router on a Stick чуть ранее, это тоже одна из реализаций Inter-VLAN routing, но на ней мы подробно останавливаться не будем, а сразу перейдем к более частому решению - коммутаторам L3 (MLS, а сейчас это вообще любой современный коммутатор) и SVI.
MLS
Как и в случае с маршрутизатором, MLS может назначить физическому интерфейсу адрес L3. Но так же у него есть возможность создавать виртуальные VLAN интерфейсы сетевого уровня - SVI. Назначенный IP-адрес на таком типе интерфейса считается шлюзом по умолчанию для любых хостов, подключенных к интерфейсу или VLAN. Соответственно этот интерфейс можно использовать для связи за пределами локальных широковещательных доменов.
Как это работает, если разбирать по шагам? Обозначим, что внутри коммутатора присутствуют виртуальные коммутаторы (они же VLAN), далее виртуальный объект пересылки. Для взаимодействия между виртуальными объектами пересылки в MLS мы создаем SVI. Далее по пунктам:
- Хост A за VLAN 10 желает передать данные хосту B за VLAN 20
- Пакет от хоста A приходит на физический интерфейс MLS и попадает на соответствющий виртуальный объект пересылки - VLAN 10
- Коммутируется на виртуальный MAC-адрес соответствующего SVI, “принадлежащий” определенному виртуальному маршрутизатору (виртуальных маршрутизаторов может быть несколько, благодаря VRF)
- Помочь перекладывать пакеты из одного VLAN в другой нам поможет “движок маршрутизации”, присутствующий в каждом MLS
- Пакет отправится на обработку либо на процессор, либо на специфический чип коммутации, где проворачивается логика с решениями “куда деть тот или иной пакет”
- “Движок маршрутизации” (т.к пакет получен на собственный MAC-адрес коммутатора т.е адресован конкретно ему) обязан распотрошить пакет. Потрошит он его вплоть до IP, по таблице маршрутизации опредяется выходной интерфейс.
- Обнаруженный выходной интерфейс и будет SVI VLAN 20
- Собирается новый пакет и отправляется в таблицу коммутации VLAN 20
- Финишная прямая, в таблице коммутации VLAN 20 определяется выходящий интерфейс в VLAN 20 и последующая отправка пакета.
Так оно и выглядело, пока основные процессы решались через process switching. Светлые головы спросили себя, а что если мы будем слать пакет напрямую?
Вопрос логичный, ведь проблема вот в чем - процесс выше, подразумевает кардинальные изменения пакета, а именно:
- полностью переписывается кадр Ethernet: переписывается адрес источника/назначения и чек-сумма
- в пакете ip переписывается TTL (уменьшается на 1) и так же пересчитывается чек-сумма
Был придуман процесс frame rewrite о котором я уже писал в предыдущей статье.
Наглядно это выглядит следующим образом (красным цветом помечены поля, требующие изменений):
 Да простит меня Иннокентий, за укарденную картинку с одного из видео.
Да простит меня Иннокентий, за укарденную картинку с одного из видео.
Оказалось, что подобные изменения легко можно уместить в логику работы TCAM, о которой так же было в предыдущей статье. Все сводится к чуть более комплексной коммутации с помощью TCAM, но все будет выглядеть так, будто это вполне себе маршрутизация.
Тут на сцену выходит CEF или topology based switching.
Как работает CEF [key topic]
CEF появился в 1996 году. Причина проста, было несколько пунктов в общем пайплайне коммутации, которые тормозили весь процесс: поиск наилучшего пути для сетей назначения, исходящего интерфейса для достижения сети назначения и, наконец, построение нового заголовка Ethernet заголовка.
CEF (Cisco Express Forwarding) - проприетарный механизм коммутации, разработанный на смену fast switching (был после process switching), который страдал посредственной масштабируемостью и отказоустойчивостью. В отличии от process switching и fast cache, CEF кеширует всю известную информацию, еще до начала передачи трафика. Чем разгружает CPU, позволяя ему заниматься более интересными задачами, чем молоть тарафик (например: маршрутизацией, формированием таблиц, управлением сети и т.п)
Архитектура CEF может быть как централизованной, так и распределенной (dCEF).
Под распределенной подразумевается использование универсальных интерфейсных процессоров (Versatile Interface Processor) или линейных карт, которые так же получают информацию от CEF и хранят ее аппаратно, используя мастер-копии от супервизоров.
Надо отметить, что даже при таком решении, все еще остаются ситуации, когда линейная карта не может обработать пакет аппаратно - это запись в таблице adjacency - Punt. Она говорит CEF, что необходимо послать такой пакет на обработку процессору (Process Switching).
CEF способен переваривать не только базовую коммутацию, но и различные задачи расчета таблиц ACL, QoS, NAT, IPSec и т.п радости, сейчас будет затронута только тема базовой коммутации пакета.
Эту информацию CEF хранит и использует в двух структурах данных, представленных следующими таблицами:
- FIB (Forwarding Information Base) таблицу, которая собирается из RIB таблицы (что и куда коммутируем)
FIB – это динамически создаваемая база данных информации, используемая маршрутизатором для принятия решений о пересылке пакетов на основе префиксов.
Когда движок маршрутизации видит изменение в топологии маршрутизации, он отправляет обновление в FIB. Каждый раз, когда таблица маршрутизации получает изменение префикса маршрута или next-hop адреса, FIB получает такое же изменение.
Как я уже писал в предыдущей статье, существует такой вид памяти как TCAM. В нее записываются расчеты CEF, например префиксы FIB.
FIB организован таким образом, чтобы оптимизировать быстрый поиск и поиск наиболее длинных совпадений (longest-prefix match). Для выполнения своей основной функции - поиска, FIB представляет из себя дерево с множеством путей (multiway trie или mtrie)
Cisco использует проприетарную форму кода trie для создания того, что они называют M-trie, который, по-видимому, представляет собой многоразрядный двоичный trie с фиксированной шириной шага 8 бит, обеспечивающий “шаг 8-8-8-8”. У Cisco также есть патент, на который ссылается то, что они называют Mtrie Plus. Cisco также имеет связанный патент на масштабирование производительности Mtrie путем репликации одного и того же Mtrie или узлов trie в нескольких банках памяти, к которым осуществляется параллельный доступ.
Mtrie - это структура данных с возможностью поиска, состоящая из узлов (node) и листьев (leaf), которая фокусируется на быстром извлечении данных, а не на основной задаче сортировки и хранения информации.
В FIB каждый узел имеет 256 дочерних элементов, которые являются указателями на более низкие уровни в структуре данных.
Шаблон шага mtrie - это количество битов, представленных каждым уровнем mtrie. В больишнстве случаев используется шаблона шага 8-8-8-8 (2^8 на уровень - 256 байт) mtrie максимальное количество уровней равно 4, а размер каждого узла будет равен 1 байт.
После 4 “уровней” покрываются все 2^32 - разрядные адреса IPv4, дочерним элементом каждого из конечных узлов (terminal leaf) октета является запись таблицы смежности CEF (сведения о следующем переходе) для этого узла (IP-маршрут):
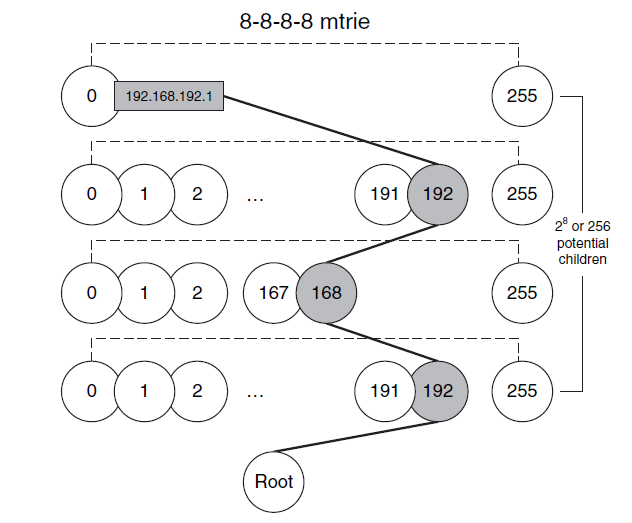 Схематичное представление концепции mtrie с шаблоном шага 8-8-8-8
Схематичное представление концепции mtrie с шаблоном шага 8-8-8-8
FIB начинается с корневого узла (Root) по умолчанию, представляющего собой отправную точку для поиска узла, представляющего данный префикс.
Реализация mtrie CEF поддерживает переменные шаблоны шага mtrie, что позволяет увеличить скорость поиска и оптимизировать использование памяти. Схема шага mtrie варьируется в зависимости от платформы.
Шаблон шага - это компромисс между использованием памяти и производительностью поиска.
Разберем на примере в eve-ng, есть следующая топология:
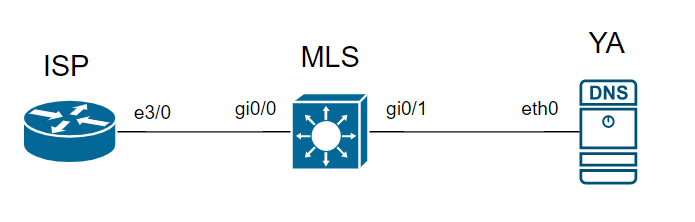
Сервер Яндекса имеет IP-адрес 77.88.8.8 и находится в условной подсетке 77.88.8.0/24. Пинговать будем с маршрутизатора условного ISP, который знает о сервере Яндекса через сеть 1.1.1.0/30 и выходящий интерейс e3/0.
Чтобы достичь 77.88.8.8, нам необходимо пройти все этапы принятия решения на маршрутизаторе ISP, куда и как нам отправить пакет.
Посмотрим show ip cef 77.88.8.8 на маршрутизаторе ISP:

Видим, что next-hop сосед у нас 1.1.1.2, через доступный интерфейс ethernet3/0.1.
С помощью show ip cef tree мы можем увидеть, какой структурой представлена FIB в данной виртуальной “железке” и какой используется шаблон шага mtrie.
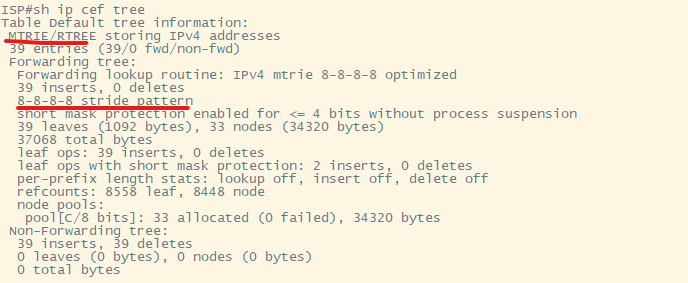
В FIB будет произведена процедура поиска по структуруе mtrie c шаблоном шага 8-8-8-8:
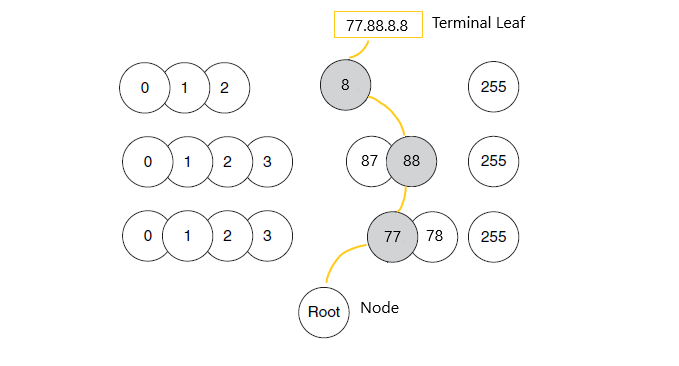
Если данный маршрут доступен в FIB (мы видели в выводе ранее, что это так), по достижению Terminal Leaf нам осталось сходить за соседом в adjacency таблицу.
- Таблица смежности (Adjacency table) - собирается из ARP таблицы, хранятся next-hop соседи (как модифицируем кадр)
Узнав next-hop и выходной интефейс из FIB, мы можем посмотреть информацию из adjacency таблицы, командой show adjacency detail чтобы получить недостающий кусок информации для отправки пакета.
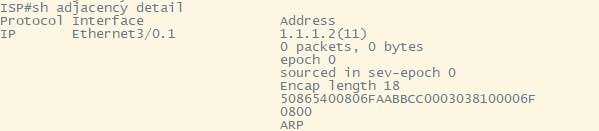
Здесь нас интересует поле готового заголовка L2:
MAC-1 MAC-2 802.1Q VLAN IPv4
50865400806F AABBCC000303 8100 006F 0800
Т.к для связи с соседом я использую сабинтерфейс, то в готовом заголовке ethernet мы видим не только базовую информацию о том как достичь соседа, но и заголовок с 802.1q вставкой, включая номер VLAN.
Подитожим, для отправки пакета через CEF необходимо две составляющие:
- исходящий интерфейс (узнаем через лукап в FIB)
- готовый заголовок L2 (узнаем в adjacency таблице)
Как выглядит общий процесс получения и отправки пакета для MLS коммутатора Cisco:
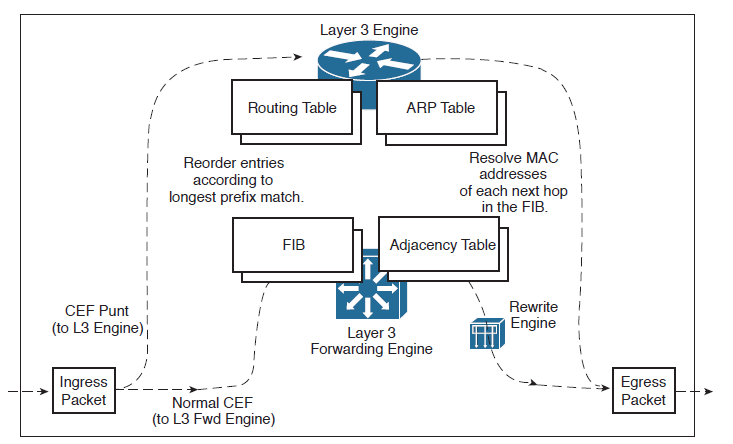
- На входящий интерфейс (ingress) приходит пакет и сохраняется в буфере памяти, называемой RX ring
- Интерфейсный процессор MLS отправляет процессору прерывание приема в случае необходимости CEF Punt. В остальных случаях (Normal CEF) коммутация происходит через движок коммутации
- MLS выполняет поиск по наибольшему совпадению для IP адреса назначения в FIB, используя IP-адрес назначения в качестве ключа поиска
- Если поиск FIB не увенчался успехом, пакет отбрасывается
- Если поиск FIB выполнен успешно, выбирается найденный маршрут. В зависимости от выбранного маршрута, обращаемся к соответствующей записи в таблице смежности. (в случае с обработкой на ASIC и подобных, это все происходит без участия процессора)
- MLS перезаписывает заголовок уровня 2, используя строку инкапсуляции из таблицы смежности, и помещает пакет в правильную очередь вывода для передачи на соответствующем исходящем интерфейсе
- Пакет, который был успешно переключен, затем ставится в очередь на TX кольцо исходящего (egress) интерфейса
Вышеобозначенный процесс CEF Punt происходит в следующих сценариях:
- Запись не может быть обнаружена в FIB
- FIB переполнена
- Значение IP TTL = 0
- Превышена максимальная единица передачи (MTU), и пакет должен быть фрагментирован
- Редирект ICMP сообщений
- Не поддерживаемый тип инкапсуляции
- Пакеты туннелируются, требуя операции сжатия или шифрования
- ACL с опцией логирования
- Требуется NAT
Есть еще одна сущность CEF, которая вклинивается между FIB и Adjacency - называется она Bucket и позволяет реализовывать CEF Load Sharing. это для тех сценрариев, когда FIB может содержать несколько вариантов next-hop соседей до одного префикса. Углубляться в это я здесь не буду т.к еще не разобрался в этой концепции.
Software/Hardware CEF
Не могу обойти стороной путаницу с software и hardware CEF. Логичный вопрос, CEF оперирует FIB и adjacency таблицей -> FIB хранится в TCAM (не только лишь, но это частные случаи) -> Вопрос: Если в маршрутизаторе (например в серии ISR4000) нет TCAM, где хранится FIB? А есть ли вооюще FIB? А если FIB нет, то CEF теряет одну из своих составляющих?
Чтобы ответить на поставленные вопросы, придется залезть чуть глубже. CEF - кусок кода, алгоритм, если хотите, который “говорит” как связать данные между собой, как, что и куда положить.
Откуда такое поведение пошло? Да очень просто, первые Catalyst 6500 были гибридные, за коммутацию отвечал CatOS, за маршрутизацию - IOS. И в гибридном IOS на первых 6500 (да и раньше) CEF был программным. Потом доделали программирование железа и монолитный IOS с тем, что называется hardware CEF.
Заглянем в книгу Cisco Express Forwarding и найдем там следующее:
Hardware-based CEF packet switching leverages the existing data structures built by CEF in software and then extends the capability to hardware by programming specialized hardware memories with information that the forwarding ASICs can use to quickly move packets for improved performance.
Имеем следующее: Если аппаратной части нет, все бремя возложено на CPU. Получаем реализацию FIB программным образом с имитацией TCAM. При наличии аппаратных ускорителей (ASIC и пр.) и соответственно TCAM, аппаратный CEF ничто иное как FIB таблицы, находящиеся внутри аппаратной начинки. CEF как таковой все тот же, просто расчеты CEF попадают в аппаратные ускорители.
Так же данные, которые мы видели выше от команд show получаются с софтовых таблиц, а чтобы получить вывод с аппаратной части, нужна команда attach module и уже внутри модуля вытаскивать диагностику, куда менее информативную (на первый взгляд), но важную на high уровнях траблшутинга.
Это все (и немножко больше) входит в рамки CCNP трека, я постарался собрать все в кучу и, возможно, что-то упустил. Дополню в процессе т.к некоторые книги еще не дочитаны, а концепции недоразобраны. Конфигурацию всего вышеописанного я оставлю на другую статью, тут и так вышло слишком объемно.
Список источников:
- Tree/Trie IP and Forwarding Lookups
- Cisco Press Cisco Express Forwarding, книга
- CISCO EXPRESS FORWARDING (2023 EDITION)
- Demystifying CEF
- Hardware-Defined Networking by Brian Petersen, книга
- CCNP and CCIE Enterprise Core ENCOR 350-401 Official Cert Guide, книга
- CCNP Routing and Switching SWITCH 300-115 Official Cert Guide, книга
- Видео с networkeducation.ru и n4e.ru
Хочешь обсудить тему?
С вопросами, комментариями и/или замечаниями, приходи в чат или подписывайся на канал.