ENCOR 350-401|Часть 3.0 - Routing concepts, IPv4
ENCOR 
Приветствую, друг.
Продолжаем двигать темы ENCOR (да, минуя тему STP/Etherchannel, которая подъедет следом уже скоро), наконец, мы добрались до роутинга. Самая жирная часть в сетях. В ней мы пройдемся по принципам маршрутизации, рассмотрим OSPF, BGP и немного EIGRP/ISIS/RIPv2 т.к у клиентов он есть, значит надо знать и уметь :)
Это вводная часть по маршрутизации, ее можно смело пропускать, если вы знакомы с базовыми концепциями маршрутизации. Это, скорее, заметка для себя + вспомнить основные моменты. Чтобы не изобретать много велосипедов, будут кросс-ссылки на статьи, где что-либо описано лучше, чем это бы сделал я.
Давно не заглядывали в блюпринт ENCOR (он, кстати, изменился, писал про это небольшую заметку)
- 3.2 Layer 3
- 3.2.a Compare routing concepts of EIGRP and OSPF (advanced distance vector vs. link state, load balancing, path selection, path operations, metrics, and area types)
- 3.2.b Configure simple OSPFv2/v3 environments, including multiple normal areas, summarization, and filtering (neighbor adjacency, point-to-point, and broadcast network types, and passive-interface)
- 3.2.c Configure and verify eBGP between directly connected neighbors (best path selection algorithm and neighbor relationships)
- 3.2.d Describe policy-based routing
Технически, это все, что есть про маршрутизацию в ENCOR. В духе предыдущих статей, все будет несколько глубже и обстоятельней. Иногда излишне, тут извините, если мне что-то интересно, это попадет в статьи.
Если нашли неточность (а их тут может быть) добро пожаловать в комментарии под постом в телеге.
Routing concepts
В сетях, переход от коммутируемой среды в маршрутизируемую ощущается так, будто занес ногу, но не ощутил под ней ступеньку. Именно отсюда начинаются сложности, хотя на вид все выглядит просто.
Итак, интернет был рожден в горниле противостояния всем известных сверхдержав, перед страхом ядерной войны.
В основе всего стоит протокол IPv4, а ныне и IPv6. В одной из предыдущих статей я уже затрагивал базовые принципы маршрутизации, в этой части разберем то, что было упущено.
Тезисно, чтобы не рвать картину, о чем там было:
- Маршрутизация требуется для устройств в разных подсетях
- Единица данных, которой принято оперировать в IP-сетях - пакет
- Чтобы отправить пакет, узлу необходимо знать next-hop IP-адрес
- Узел сперва использует LPM (Longest prefix match). А если LPM несколько?
- Получены через один протокол маршрутизации
- выбирается по наименьшей метрике, правила зависят от протоколов маршрутизации
- Получены от разных протоколов маршрутизации
- выбирается по наименьшей административной дистанции (AD)
- Получены через один протокол маршрутизации
- Далее нужно выбрать исходящий интерфейс и скоммутировать пакет, для этого есть две сущности: RIB (Control plane) и FIB (Data plane):
- RIB впитывает в себя информацию из:
- статических маршрутов
- из процессов динамических протоколов маршрутизации
- FIB слепок RIB (он же часть CEF у Cisco) для ускорения принятия коммутационного решения т.е поиска исходящего интерфейса (и не только)
- FIB бывает как программный так и аппаратный, зависит от платформы
- RIB впитывает в себя информацию из:
- Возможные методы балансировки (CEF, ECMP и т.д)
Вся эта ядерная смесь склеивается IP протоколом - RFC 791. Именно он инкапсулируется в ethernet и именно в него инкапсулируются UDP/TCP.
Взаимодействие между узлами в интернете построено на протоколе IP. Интернет - это набор AS (Autonomous System), связанных между собой.
Прелесть и проклятье IP - он ненадежен т.к не имеет механизмов гарантии доставки. Его основная задача - выжить любой ценой.
Изначально маршрутизатор знает о тех сетях, которые к нему подключены (directly connected).
Чтобы двинуться за его пределы, самое простое - это назначить маршрут по умолчанию. Чуть сложнее, это указать static route, что прямо скажет маршрутизатору куда отправлять пакет для достижения определенной сети.
Представим, что таких маршрутов десятки или сотни. Крайне трудоемко, верно? Тут мы воспользуемся протоколами динамической маршрутизации (OSPF, ISIS, BGP), чтобы маршрутизатор сам разбирался что происходит внутри сети.
Тут важно иметь представление, как все это работает на практике, и если вы еще не, то эту задачу уже решили в СДСМ:
- Сети для самых маленьких. Часть третья
- Как разберетесь, можно попробовать добить статьей про статические маршруты в Cisco IOS, которые не так просты, как кажется. Там же узнаете, почему ip route 0.0.0.0 0.0.0.0 gi0/0 - плохо.
Минимальная единица в интернете - узел (ПК, сервер, маршрутизатор, коммутатор и т.п), узлы могут быть конечными и транзитными, но их объединяет необходимость иметь IP-адрес. Чтобы в дальнейшем не возвращаться к этой теме, в 100-й раз пройдемся по заголовку IPv4, который я, например, так и не доразобрал для себя. А в следующий раз, после протоколов динамической маршрутизации, захватим и IPv6, все же 2023 год на дворе, пора уже.
IPv4
IP-адрес это простое число - 32 бита. Четкого протокола записи IP адреса не утверждено, но стандартный способ, в виде 4 октетов, разделенные точкой - 192.168.0.1. Сомневаетесь? Выполните ping 2130706433 :)
Адрес должен быть уникальным в пределах подсети иначе, чаще всего, получите конфликт адресов. (Anycast пока не трогаем)
IP-адрес состоит из двух частей:
| Network ID | Host ID |
Network ID: По этой части хосты ориентируются, находятся они в одной сети или нет.
- обязан совпадать у всех хостов в сети
- обязан различаться у хостов в разных сетях
Host ID: Уникально идентифицирует хост.
- выбирается самостоятельно и зависит от **маски подсети
Как быстро понять, находятся ли хосты в одной сети?
Нам понадобится magic-число - 256, которое не иначе как 2^8
Есть два IP-адреса 172.16.1.1 и 172.16.5.1, с маской /20. Нужно понять, в одной сети находятся хосты или нет.
- Перевод маски в 10-й формат: 255.255.240.0
- Вычитаем из магического числа октет, не равный 1 или 0: 256-240 = 16
- Получили число 16, что дает нам понять, что сети будут делиться с шагом 16: 172.16.0.0 172.16.1.1 <- 172.16.5.1 <- 172.16.16.0 172.16.32.0 …
Хосты находятся в одной сети - 172.16.0.0/20
Заголовок IPv4
Сразу поглядим на заголовок в Wireshark, с 4.0 версии он позволяет включить отображение структуры заголовка:

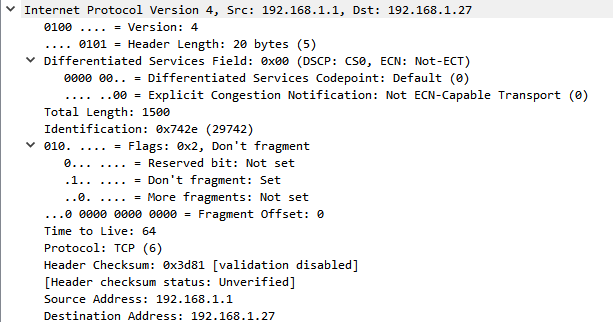
Это пакет от взаимодействия с моим домашним роутером, что в нем есть:
Version (4 бита): Она же версия протокола IP. 0100 - IPv4, 0110 - IPv6.
Internet header Length (4 бита): Отображают размер заголовка в машинных словах, включая опции (идут после адреса назначения и редко используются), чтобы узел понимал, где заканчивается заголовок и начинаются данные.
- Без поля опций, поле IHL равно 20 байтам == 5 машинным словам.
- Часто в пакете отображается числом 0101 - 5
- Максимальный размер IP заголовка ограничен полем IHL и может достигать 60 байт. (включая поля опций = 40 байт) что в переводе на машинный == 15 машинным словам или двоичному числу 1111.
Differentiated Services Field (8 бит): Ранее это было поле ToS (Type of Service), ныне это разделение на DSCP и ECN. Оно есть, но чаще всего не используется и равно 0x00.
DSCP (6 бит): Используется для определения приоритета IP-пакета. Эдакий QoS.
ECN (2 бита): Используется для flow control (управления перегрузками) т.е если сеть перегружена, узел может отметить это в ECN поле и получатель сможет предпринятть некоторые меры.
Почитать подробнее можно в наборе RFC или более сжато в статье.
Total length (16 бит): Указывает полный размер IPv4 пакета, включая опции и данные за ним.
С первым машинным словом разобрались, резюмируем: Version и IHL будет, чаще всего, одинаковым по значению, в контексте IPv4, DSF чаще всего не используется, просто помним, что оно есть и для чего нужно, Total length важное поле, которое дает понимание о размере IP пакета.
- Максимальный размер поля может быть 65535 байт
- Любой узел обязан поддерживать размер 576 байт
Далее, логичней будет запомнить четвертое и пятое машинные слова т.к они представляют из себя Source address и Destination address соответственно.
- В процессе маршрутизации данные поля не изменяются, в отличии от SRC/DST Ethernet заголовка
- За исключением технологии NAT, но о нем позже
Далее вернемся обратно на третье машинное слово, которое состоит из TTL, Protocol и Header Checksum
TTL (8 бит): Наиболее известный параметр IP-пакета, который позволяет избежать петель маршрутизации на сетевом уровне. На каждом хопе TTL уменьшается на 1 (то, чего не хватает Ethernet)
Разные семейства ОС используют по умолчанию разный TTL. В случае нашего пример, это значение 64 т.к в Keenetic ОС основана на NDMS 2, которая, в свою очередь, основана на Linux. Для Windows, например, значение TTL = 128
- Максимальное значение, которое можно разместить в этом поле - 255
Protocol (8 бит): В это поле вкладывается номер протокола, который лежит внутри IP. Используется для того, чтобы узел понял, куда дальше передать пакет на обработку. Вот некоторые из актуальных:
- 6 - TCP
- 17 - UDP
- 1 - ICMP
- 47 - GRE
- 50 - ESP (IPSEC)
Полный список можно найти на сайте iana.
Header checksum (16 бит): Проверяет корректность заголовка IPv4 (без данных), использует алгоритм Internet Checksum.
Осталось разобраться со вторым машинным словом, которое включает в себя Identifictaion, Flags, Fragment Offset. Оно, на самом деле, не такое уж и страшное, по причине того, что в современных сетях, чаще всего, пакеты принято не доводить до фрагментирования, но это поведение все еще имеет место быть.
Все три поля относятся к процедуре фрагментации. Фрагментация - разделение IP пакета на несколько пакетов поменьше.
Здесь всплывает такой параметр, как MTU. Это некоторое ограничение, превышая которое, IP-пакет должен быть фрагментирован или отброшен (если установлен флаг DF).
MTU, по сути своей, еще одна неоднозначная вещь, которую все понимают как хотят, в силу посильной помощи от крупных вендоров, вносящих еще больше путаницы. Я посчитал нужным немного прояснить этот момент.
Воспользуемся забавной аналогией, которая будет основана на вполне реальном RFC - IP over почтовый голубь (RFC 1149).
Голубь - наша “ethernet” среда. Он носит ленточки с неким количеством символов. Если голубь может нести ленточку длиной 1500 символов, но не больше, то MTU следует назначить 1500. Чтобы нам не пришлось набирать дополнительных голубей (а это накладные расходы!) чтобы нести части одной большой ленточки до пункта назначения.
Пакет, который несет голубь, не имеет внутри информации об MTU. Что говорит нам о том, что MTU - локальная вещь на каждом отдельном узле.
Отсюда мы выносим несколько утверждений:
- MTU существует в IP и это цыфирька, больше которой не может быть полный размер отправляемого пакета, включая все заголовки (в ipv4 - total length).
- MTU в ethernet не существует от слова совсем. Так же как и нет всяких L2MTU и прочих сущностей. Просто в какой-то момент аббревиатуру “MTU” стало удобно применять на каждом из уровней OSI.
Применительно к реальному миру, где все вращается вокруг интерфейсов, поэтому мы видим MTU в каждом из них.
Interface mtu - предписывает, что нельзя отправлять ip-пакеты больше указанного размера в этот интерфейс. interface mtu обычно задается в конфиге. Тот самый IP MTU.
Это IP MTU:

А это размер пакета:

Path mtu - нельзя отправлять пакеты больше указанного до указанного получателя. Path mtu обычно вычисляется в результате использования механизмов PMTUD.
Классический “ручной” способ определения MTU это утилита ping. Выставляем размер пакета, например 1500 и добавляем флаг “не фрагментировать”. Далее снижаем размер пакета до момента, пока ping не отработает корректно.
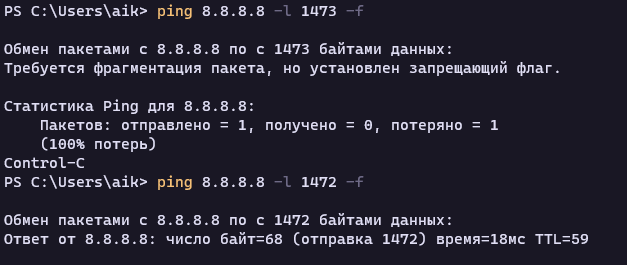
В моем случае это значение 1472 байта. Но это еще не значение MTU провайдера, сейчас мы нашли максимальный размер блока данных, без учета заголовков ICMP и IP т.е это TCP MSS.
MTU = MSS + IP + ICMP = 1472 + 20 + 8 = 1500 байт
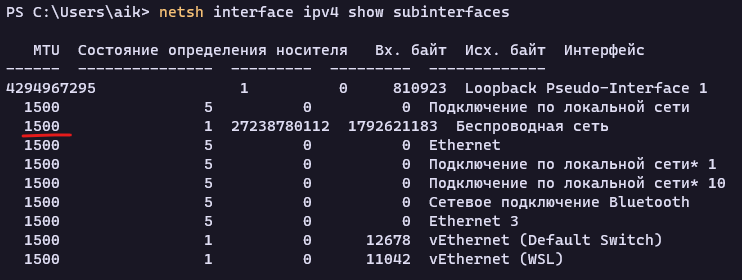
Так же можно воспользоваться netsh и командой netsh interface ipv4 show subinterfaces:
Сейчас 2023 год, у нас кругом Ethernet, остается вопрос, если связь с размером вложения в Ethernet и MTU таки прослеживается, почему MTU именно 1500 байт? Причем оно не “максимальное”, есть ведь Jumbo-фреймы, например. Да и вообще, нет термина “максимальное вложение” для Ethernet.
Четкого и полного ответа тут нет, но есть несколько предположений, вращающихся вокруг одной темы - CRC32. За поток сознания спасибо Иннокентию.
Чтобы не раздувать статью, положу под спойлер цепочку мыслей на эту тему, а вы делайте с этой информацией что хотите :)
Почему MTU в современном интернете 1500 байт?
- Соображение №1: Почему 1500 байт? Потому что вложение, максимальное для ethernet = 1500 байт.
- Соображение №2: Почему вложение в ethernet 1500 байт? Потому что CRC32.
- Соображение №3: Почему в Token Ring-е 1500 байт (на основе которого отчасти сделан Ethernet)? Потому что бессердечная сука математика.
Тут чуть подробнее. Отправитель формирует заголовки и данные, считает от всего этого, на лету, чексумму по алгоритму CRC32 и записывает в трейлер. В TR используется тот же алгоритм CRC, что и в Ethernet.
Получатель, принимающий некоторый поток байт, предположительно являющуюся пакетом Ethernet, TR, не суть важно, он считает ту же самую чексумму. Должно получиться то же самое значение, так устроена математика алгоритма.
Если обобщать, мы имеем некоторый простой и эффективный механизм проверки на целостность куска данных, переданных по некоторой среде. Если хотя бы один бит по дороге поломался, чексумма у получателя не сойдется, что прямо указывает на то, что этот кусок данных не валиден и его даже не нужно пытаться обработать.
Закрепили. Теперь немного глубже. Если мы берем некий пакет и "подписываем" его чексуммой по алгоритму CRC32, то, по сути, мы считаем хэш-функцию от заголовка и данных пакета и помещаем ее в трейлер. Как и у любой хэш-функции, у CRC32 бывают коллизии.
Если не знакомы с коллизиями хэш-функций, добро пожаловать в статью на хабре, где описан живой пример на примере MAC-адресов.
Коротко, это та ситуация, когда у нас результирующее значение работы CRC32 будет одинаковым для двух разных пакетов. Потому что, условно, мы берем 1-1.5Кб пакет и сворачиваем его в 4 байта. Это означает, что таких "одинаковых" пакетов может быть достаточно много. Вот тут вступает в дело CRC32, которая гарантирует, что если некоторое (пока условное) количество бит будет повреждено, то чексумма будет отличаться сильно.
Отсюда вывод: если пакеты маленькие, вероятность коллизии будет крайне мала. Но вот если пакеты начнут расти в размере, вероятность коллизии существенно возрастет. Поэтому слишком большие пакеты делать нельзя и нужно найти золотую середину.
- Соображение №4: Речь идет о технологиях 1970 годов, в то время протокол должен был отвечать требованиям системы, а именно RAM. Пакетам надобно буферы, а самая минимальная RAM на тот момент, в продвинутом Apple II = 4КБ.
- Соображение №5: Какова вероятность того, что одиночный бит поменяется?
Что же такое CRC и как она работает?
Для начала, определим понятие контрольная сумма – это метод проверки целостности принятой информации на стороне приёмника при передаче по каналам связи.
CRC (Cyclic redundency check) - по сути результат деления данных на константу - полином (многочлен). В формирование CRC вносит вклад каждый байт, что дает ту самую гарантию, что результат изменится, если хотя бы один бит поменяется.
Полином - представляет собой выражение, которое состоит из переменных (обычно обозначаемых буквой "x"), а также числовых коэффициентов, умноженных на степени переменной. Например, x^2 + 3x - 4 - это полином второй степени, где x возводится во вторую степень (x^2), умножается на коэффициент 1 (т.к нет иного числа) + x возводится в первую степень (x) умножается на коэффициент 3 + константа -4.
Полином, используемый для расчета CRC32 в ieee 802.3 - 0x04C11DB7 = x³² + x²⁶ + x²³ + x²² + x¹⁶ + x¹² + x¹¹ + x¹⁰ + x⁸ + x⁷ + x⁵ + x³ + x² + 1
Матиматику самого алгоритма оставим за скобками. Я лишь попытался объяснить составляющие части для работы CRC32.
В контексте CRC каждый бит входных данных рассматривается как коэффициент полинома, а выходная контрольная сумма - это результат применения полинома к входным данным.
Вывод: CRC32 позволяет нам защищаться от некоторого количества поврежденных бит в разных местах принимаемого потока бит. Основная идея - не должно быть слишком много подобных битых битов. Закрепили.
Вероятность изменения одиночного бита (оно же bit error rate или BER) для Ethernet ~ 10^-12 т.е примерно 1 ошибка на триллион переданных бит. Тут важно заметить, что это не точное значение и конечный результат будет зависеть от многих факторов, таких как качество физической среды передачи, уровень помех, наличие ошибок на устройствах в сети и т.д. В реальных условиях, BER может быть выше или ниже этой оценки.
Т.е для каждого, отдельно взятого бита, вероятность изменения будет равна 10^-12.
Основываясь на этой информации, если мы берем большой пакет, суммарная вероятность ошибки возрастает. Именно поэтому, мы не должны передавать много битов подряд, чтобы их можно было корректно обработать. Закрепили. Много закреплять придется...
Логично предположить, что и вероятность коллизий CRC32 так же будет возрастать. Поэтому вероятность того, что произойдет ошибка и CRC32 эту ошибку не поймать, растет в зависимости от количества байт в пакете.
Соотношение, с какой вероятностью CRC32 ловит ошибку к 4 байтам чексуммы от полезной нагрузки, в результате даст некий экстремум (полезный максимум) этой функции ~ на границе 12000 бит == 1500 байт, при котором чексумма будет отрабатывать наиболее эффективно.
Т.е пакеты 12000 бит наиболее эффективно используют 4 байта чексуммы, чтобы корректно отлавливать ошибки, если в CRC32 пихать больше байт, то функция будет работать все менее эффективно.
Еще немного ликбеза про CRC, полиномы и что такое Расстояние Хэмминга или HD.
- Соображение №6 (вытекающее из №5): Когда пакет слишком большой и в нем слишком много бит поменялось, может возникнуть коллизия CRC32.
На определенного размера пакетов если у нас произошла 1 ошибка, то мы гарантированно знаем, что чексумма поменяется, если у нас пакет был до n-бит размером. Если произошло 2 ошибки (2 бита) мы тоже знаем, что чексумма так же поймает, но гарантия будет распространяться на пакет уже меньшего размера т.к для большего уже не факт. Для Ethernet 12000 бит = 1500КБ функция CRC32 гарантирует, что она ловит независимых 3 бита с ошибкой, расстояние Хэмминга HD=4. Если мы начинаем растить длину пакета. она перестает гарантировать, что будет ловить те же 3 бита.
Есть некоторое число, точного значения я не знаю, т.к есть данные, что это число 9300 байт, я нашел лишь единственную таблицу с данными, в публикации 32-Bit Cyclic Redundancy Codes for Internet Applications.
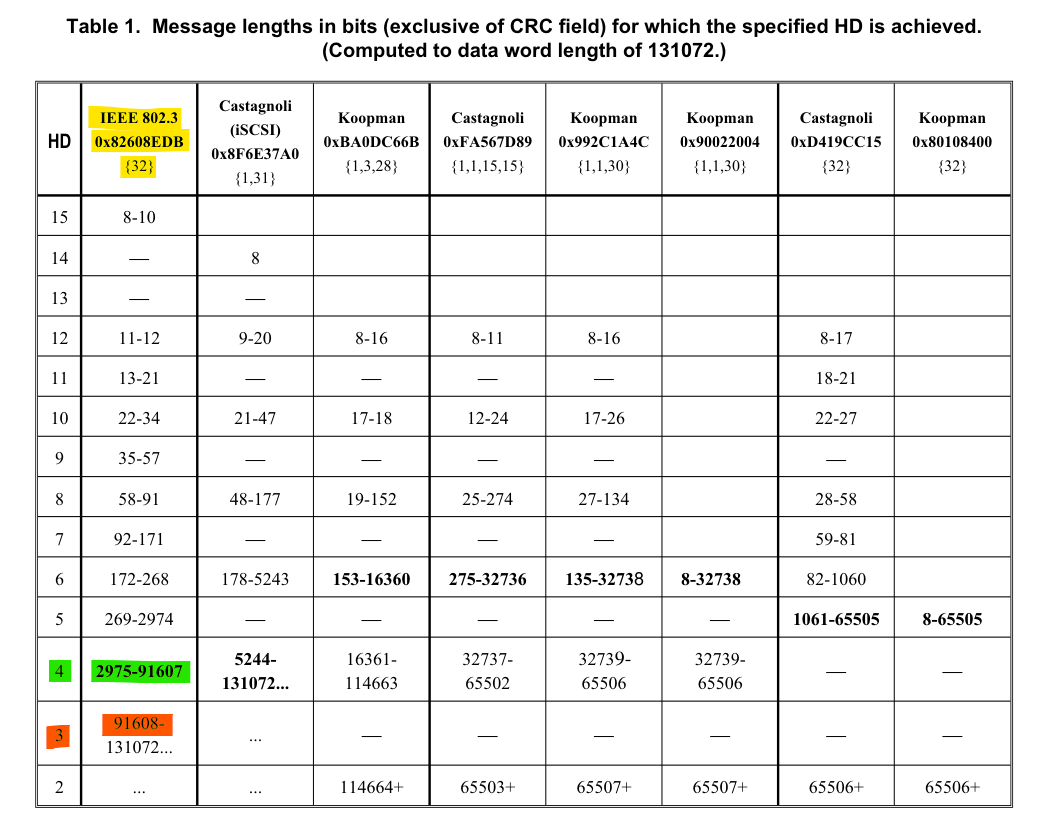
В данной таблице HD=4 меняется на HD=3 начиная с размера пакета в 11451 байт. Изменение расстояние Хэмминга это скачкообразное падение эффективности, т.е вместо 3 ошибок, функция начинает ловить 2.
Вывод: 1500 байт - потому что это наиболее эффективное (на момент утверждения стандарта) значение в максимуме (12000 бит) функции CRC32, которая ловит ошибки при их наличии. Отсюда и размер Jumbo-фреймов на границе 9000 байт, потому что дальше уже увеличивать размер пакетов на свой страх и риск.
Есть и более совершенные полиномы, например CRC32C, которые, в том числе, рекомендовались к использованию в Jumbo-фреймах, но это уже совсем другая история.
Интересная статья с еще одним размышлением на тему, от Бена Кокса.
Публикации по CRC я положил в ЯД/Доп. материалы/Научные работы/CRC.
С MTU разобрались, теперь, наконец, добьем поля по фрагментации.
Identification (16 бит): Некоторое число, которое проставляется узлом для каждого пакета. ID возрастает на единицу у каждого следующего уникального пакета. Если где-то на пути произойдет фрагментация, у мелких кусочков фрагментированного пакета это поле наследуется от оригинального пакета. Подобный механизм позволяет понять принадлежность фрагментированных пакетов.
Fragment Offcet (13 бит): Указывает смещение данных фрагмента относительно оригинального пакета. Позволяет собрать пакет в на стороне получателя в нужном порядке.
При размере поля в 13 бит, внутрь можно поместить не больше 8КБ значения или 8192 байта. Как быть, если мы передаем пакет, например, 65500?
Выход из положения заключался в том, чтобы вписывать в это поле не сам размер, а число, которое получается при делении на 8. Получается, что фрагментация происходит блоками, по границе 8 байт.
Flags (3 бита):
- Reserved bit: Всегда 0
- Don’t fragment (DF): 1 - если отправитель запретил фрагментацию пакета. В остальном 0. Используется в PMTUD
- More fragments (MF): 1 - для всех фрагментов, кроме последнего. В остальном 0
В конце идут поля Options, о них можно прочитать в RFC т.к они нигде не используются.
В Options так же входит Padding, если включены одна или несколько опций, и количество используемых для них битов не кратно 32, добавляется достаточное количество нулевых битов, чтобы «расширить» заголовок до числа, кратного 32 битам (4 байта).
Этого будет достаточно, чтобы вспомнить, что из себя представляет IPv4, взаимодействие между хостами, думаю, вы себе представляете, так же как и работу ICMP, APR, DHCP, DNS, разве что NAT придется затронуть отдельно т.к он есть в блупринте ENCOR.
Если нет, рекомендую посмотреть бесплатную серию вебинаров у Иннокентия на NetworkEducation.
С повторением основ закончили, со следующей статьи приступим к основному блюду - протоколы динамической маршрутизации. Их у нас имеется 5 штук:
- Routing Information Protocol Version 2 (RIPv2) - технически мертв, но кое-где его интересно используют, потому что простой)
- Enhanced Interior Gateway Routing (EIGRP) - проприетарная технология, которая кое-где встречается
- Open Shortest Path First (OSPF) - открытый протокол, используется в виде OSPFv2/v3
- Intermediate System-to-Intermediate System (IS-IS) - сам не видел, но старшие коллеги нахваливают и используют :)
- Border Gateway Protocol (BGP) - тут понятно без комментариев
Протоколы выделенные жирным шрифтом я буду разбирать подробно, протоколы выделенные курсивом я рассмотрю как факультатив, потому что интересно. Начнем с OSPF и т.к тема для текстового представления не так проста, постараюсь придумать интерактив.
Хочешь обсудить тему?
С вопросами, комментариями и/или замечаниями, приходи в чат или подписывайся на канал.