Перевод|Network Automation 101
Translation 
Эта статья - адапатированный перевод статьи Дмитрия Тесли. Одобрение от автора получено, поэтому читаем на здоровье!
Я решил заняться переводом, в первую очередь, для того, чтобы обозначить некоторую точку отсчета моих изысканий. Статья Дмитрия оказалась к месту. Основная цель - обзорная экскурсия по инструментарию и известным практикам.
Я за то, чтобы впитывать оригинал (постигая английский), но, например, год назад я и сам бы не полез ее читать. Настолько английский был не в приоритете.
Работая сетевиком в небольшой конторе, сложно сразу понять, куда копать. Информации очень много, а чтобы постичь неизвестную сферу, придется с чего-то начинать. А уж в рамках автоматизации, хочется не отставать от глобальных трендов развития сетевого инженера, верно? Поэтому, считаю крайне важным наличие подобных переводов в RU сегменте. (подобным частенько занимаются люди на хабре, но дальше самого перевода дело, обычно, не идет). Постараемся сдвинуть эту тему с мертвой точки.
В переводе постараюсь не искажать англоязычные термины и указывать их “как есть”, за редкими исключениями, в таком случае, оригинальное название укажу в скобках.
По ходу статьи я буду вставлять свои мысли по тем или иным вопросам и выделять подобное следующим образом. Мыслей не так много, ибо не хотелось сильно оттенять общий посыл оригинальной статьи, а так же сказывается недостаток экспертности в исследуемом вопросе.
Так же, хочу заметить, что статья Дмитрия, так или иначе, пересекается с недавно опубликованной статьей Марата Сибгатулина (aka eucariot), АДСМ5. История сетевой автоматизации, которая подробнее освещает многие, описанные здесь, инструменты. Рекомендую ознакомиться и с ней, после того, как осилите эту.
Table of contents
- DevOps
- NetDevOps
- Data Models and Encodings
- Technologies
- Automation Tools
- Text Editors
- Conclusion
- Social Media Resources
- References and further reading
DevOps
Чтобы разобраться в вопросе, начнем с истоков. В некотором роде, автоматизация сетей существует уже довольно давно. Вы можете вспомнить такие примеры, как использование Expect, выполнение сценариев, которые получают полезную информацию от сетевых устройств через SNMP. Что же изменилось с тех пор? Почему автоматизация сети является такой актуальной темой в настоящее время? Ответ - подъем движения DevOps.
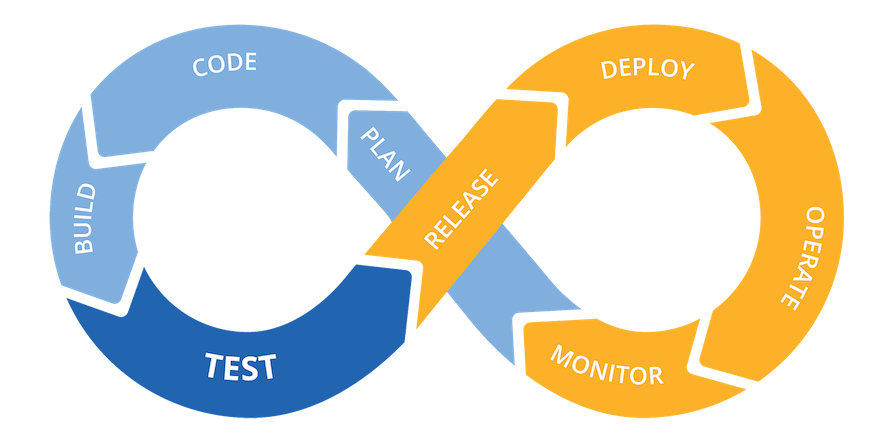
Термин “DevOps” впервые появился где-то в 2008-2009 годах и приписывается Патрику Дебуа. В 2009 году он провел мероприятие под названием “DevOpsDays”, основной целью которого было собрать вместе разработчиков и системных администраторов и обсудить способы преодоления разрыва между ними. Это набрало достаточную популярность, и DevOps стал набившим оскомину словом.
Но что такое DevOps? Академического определения не существует, но наиболее распространенное гласит, что это набор инструментов, практик и философий, направленных на преодоление разрыва между командами разработчиков и системными администраторами, чтобы быстрее создавать качественное программное обеспечение.
Мой скудный словарный запас не позволил перевести это как-то иначе, поэтому под “разрывом” подразумеваются частые недопонимания между командами разработчиков и эксплуатационщиков. Должны ли сисадмини понимать код? Обязаны ли разработчики вникать в сетевые проблемы? и т.п вопросы, возникающие то тут, то там.
DevOps имеет множество аспектов, но мы сосредоточимся на трех ключевых практиках, которые он предлагает: Инфраструктура как код, CI/CD и контроль версий.
Infrastructure as Code
Согласно Википедии, IaC - это …
… процесс управления и обеспечения центров обработки данных с помощью машиночитаемых файлов, вместо физической конфигурации оборудования или интерактивных инструментов конфигурирования.
Что это означает? У вас есть куча текстовых файлов, в которых вы определяете желаемое состояние вашей инфраструктуры: количество виртуальных машин, их свойства, виртуальные сети, IP-адреса и т.д. Затем эти файлы обрабатываются IaC-инструментом или фреймворком (Terraform, SaltStack, Ansible - это лишь несколько примеров), который переводит это объявленное состояние в фактические вызовы API и конфигурационные файлы и применяет их к инфраструктуре, чтобы привести ее в желаемое состояние. Это дает вам уровень абстракции, поскольку вы сосредотачиваетесь только на результирующем состоянии, а не на том, как его достичь. Здесь я должен упомянуть одну из ключевых особенностей подхода IaC - идемпотентность. Эта фича позволяет запускать инструмент IaC многократно, и если что-то уже находится в нужном состоянии, это не будет затронуто. Например, если вы объявите, что определенный VLAN должна быть настроен на коммутаторе, а он уже там есть, когда вы запустите инструмент IaC на этом коммутаторе, он не будет пытаться ничего настроить.
Обращение с инфраструктурой как с текстовыми файлами, позволяет применять к инфраструктуре те же инструменты и методы, что и к любому другому программному проекту. Основными примерами здесь являются CI/CD и контроль версий.
CI/CD
CI/CD означает Continuous Integration / Continuous Delivery или Deployment. Давайте рассмотрим каждый компонент более подробно.
Continuous Integration - процесс частого (до нескольких раз в день) слияния (merge) изменений кода в основной репозиторий кода. Эти слияния сопровождаются различными тестами и процессами контроля качества, такими как unit и integration тесты, статический анализ кода, извлечение документации из исходного кода и т.д. Такой подход позволяет интегрировать изменения кода, часто вносимые разными разработчиками, что снижает риски возникновения конфликтов интеграции.
Continuous Delivery - расширение CI, которое заботится об автоматизации процесса выпуска (например упаковка, создание образа и т.д.). Continuous Delivery позволяет развернуть приложение в производственной среде в любое время.
Continuous Deployment - продолжение continuous delivery, но на этот раз развертывание (deployment) в производство также автоматизировано.
Version control
Система контроля версий - это основа любого проекта автоматизации. Он отслеживает изменения в файлах вашего проекта (исходный код), регистрирует, кто внес эти изменения, и обеспечивает рабочие процессы CI/CD.
Сегодня Git является стандартом де-факто в системах контроля версий. По сути, Git - это просто инструмент командной строки (хотя и очень мощный), который управляет версионированием проекта, путем создания и манипулирования метаданными, хранящимися в отдельном скрытом каталоге, в рабочем каталоге проекта. Но все волшебство приходит с веб-системами контроля исходных текстов, такими как GitHub или GitLab и др.
Многие путают Git и GitHub, поскольку последний стал общим термином для систем контроля версий.
Предположим, вы работаете в команде разработчиков над проектом, размещенным на GitHub. Ваш типичный рабочий процесс будет выглядеть следующим образом:
- Вы хотите внести изменения в исходный код. Это может быть исправление ошибки или новая функция. Вы создаете новую ветку (branch) от основной (main) и начинаете делать коммиты ( commits). Это никак не влияет на основную ветку.
- Когда работа кажется законченной, самое время создать запрос на вливание изменений (pull request). PR - это способ сообщить другим разработчикам, что вы хотите объединить свою ветку с основной. Создание PR может запускать CI-тесты, если они настроены. После успешного прохождения всех CI-тестов, код проверяется другими членами команды. Если CI-тесты провалены или что-то нуждается в доработке, PR будет отклонен. Затем вы можете исправить свой код в той же ветке и создать еще один PR.
Обычно PR никогда не объединяются автоматически, и кто-то должен принять окончательное решение.
- Если все в порядке, ваша ветка будет объединена с основной.
- Если CD настроен, слияние с основной веткой запускает развертывание в производственной среде
Summary
В этом разделе я дал краткий обзор того, что такое DevOps, его основных инструментов и практик. В следующем разделе я постараюсь объяснить, как его можно применить к сетям и автоматизации сетей.
NetDevOps
Теперь, когда вы прочитали предыдущий раздел, вы должны догадаться, что NetDevOps - это просто подход DevOps, примененный к сетевым технологиям. Все вышеупомянутые ключевые практики DevOps могут быть согласованы с сетью. Конфигурации устройств могут быть шаблонными (IaC) и помещены в систему контроля версий, где применяются процессы CI/CD.
Ниже приведен пример диаграммы, представляющей весь процесс.
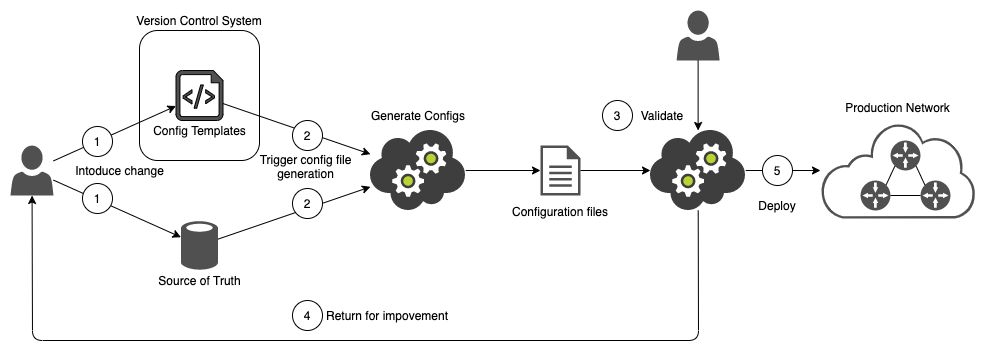
Рабочий процесс начинается с того, что оператор сети вносит изменение (1) либо в Source of Truth, либо в configuration templates. Так что же это такое?
Source of Truth - база данных (например. SQL DB или обычные текстовые файлы), где хранятся такие константы, как номера VLAN и IP-адреса. На самом деле, это может быть несколько баз данных - вы можете получить информацию об IP из IPAM и описания интерфейсов из DCIM (Netbox - отличный пример, который может делать и то, и другое). Ключевая идея здесь заключается в том, что каждая база данных должна быть единственным источником истины для конкретной части информации, поэтому, когда вам нужно что-то изменить, вы изменяете это только в одном месте.
Netbox - отличный инструмент для старта в автоматизации. На мой взгляд. Это комплексный продукт, который имеет задокументированное API, сущестует уже 6 год подряд и постоянно обновляется. Ansible или Nornir (если есть понимание Python) в руки, разворачиваешь Netbox, создаешь несколько тестовых нод и пробуешь ими рулить постепенно подключая Netbox.Эту тему планирую развивать в будущих статьях.
Пара интересных мысле на тему SoT в статье от Night_Snake.
Configuration templates - это просто текстовые файлы, написанные на выбранном вами языке шаблонов (я думаю, Jinja2 - самый популярный). В сочетании с информацией из SoT они создают конфигурационные файлы для конкретного устройства. Шаблонизация позволяет разбивать конфигурации устройств на отдельные файлы шаблонов, каждый из которых представляет определенный раздел конфигурации, а затем смешивать и сопоставлять их для создания конфигураций для различных сетевых устройств. Некоторые шаблоны могут повторно использоваться на нескольких устройствах, а некоторые могут быть созданы для определенных версий программного обеспечения или производителей.
Внесение изменений в SoT или шаблоны запускает (2) весь остальной процесс. Во-первых, оба эти источника информации используются системой управления конфигурацией (напр. Ansible, подробнее об этом позже) для создания результирующих конфигурационных файлов, которые будут применены к сетевым устройствам. Затем эти конфигурации должны быть проверены (3). Валидация, обычно, включает несколько автоматизированных тестов (проверка синтаксиса, использование программного обеспечения для моделирования, запуск виртуальных устройств) и рецензирование (peer review). В случае неудачи валидации, инициатору изменений (4) предоставляется обратная связь в той или иной форме, чтобы он мог исправить ситуацию и начать весь процесс заново. Если проверка пройдена, полученные конфигурации могут быть развернуты в производственной сети (5).
Конечно, представленный рабочий процесс достаточно схематичен и призван дать общее представление о процессе автоматизации сети и роли основных компонентов в нем.
В следующем разделе я рассмотрю инструменты и технологии, которые можно использовать в рабочих процессах автоматизации сети.
Data Models and Encodings
Понимание того, как данные могут быть структурированы и закодированы, очень важно в программировании в целом и в сетевой автоматизации в частности.
YANG & Openconfig
YANG (Yet Another Next Generation) - это язык представления данных, первоначально разработанный для NETCONF и определенный в RFC 6020, а затем обновленный в RFC 7950. YANG и NETCONF можно рассматривать как преемников SMIng и SNMP соответственно.
YANG предоставляет независимый от формата способ описания модели данных, которая может быть представлена в XML или JSON.
Джейсон Эдельман, Скотт С. Лоу, Мэтт Освальт. Программируемость и автоматизация сетей, стр. 183
Существуют сотни моделей данных YANG, как vendor-neutral, так и vendor-specific. Веб-сайт YANG Catalog может быть полезен, если вам нужно найти модели данных, соответствующие вашим задачам.
Из-за такого обилия моделей данных и отсутствия координации между организациями, разрабатывающими стандарты, и поставщиками, кажется, что YANG и NETCONF идут тем же путем, что и SNMP (т.е. используется только для поиска данных, но не для конфигурации).
Рабочая группа OpenConfig пытается решить эту проблему путем предоставления нейтральных к производителю моделей данных, но, я думаю, что точка зрения Ивана Пепельняка, высказанная в 2018 году, о том, что “бесшовная конфигурация сетевых устройств от разных производителей все еще остается несбыточной мечтой”, сохраняется и в 2020 году.
XML
XML (eXtensible Markup Language), хоть и немного устарел, все еще широко используется в различных API. Он использует теги для кодирования данных, поэтому его трудно прочитать человеку. Изначально он был разработан для документов, но подходит для представления произвольных структур данных.
Вы можете обратиться к этому гайду, чтобы узнать больше о XML.
Давайте посмотрим, как этот пример вывода команды Cisco IOS show vlan из CLI может быть закодирован с помощью XML:
VLAN Name Status Ports
---- -------------------------------- --------- -------------------------------
1 default active Gi3/4, Gi3/5, Gi4/11
<...>
VLAN Type SAID MTU Parent RingNo BridgeNo Stp BrdgMode Trans1 Trans2
---- ----- ---------- ----- ------ ------ -------- ---- -------- ------ ------
1 enet 100001 1500 - - - - - 0 0
Так это выглядит в XML:
<?xml version="1.0" encoding="UTF-8" ?>
<root>
<vlans>
<1>
<interfaces>GigabitEthernet3/4</interfaces>
<interfaces>GigabitEthernet3/5</interfaces>
<interfaces>GigabitEthernet4/11</interfaces>
<mtu>1500</mtu>
<name>default</name>
<said>100001</said>
<shutdown>false</shutdown>
<state>active</state>
<trans1>0</trans1>
<trans2>0</trans2>
<type>enet</type>
<vlan_id>1</vlan_id>
</1>
</vlans>
</root>
YAML
YAML (YAML Ain’t Markup Language) - это удобный для человека формат сериализации данных. Поскольку YAML очень легко читать и писать, он широко используется в современных инструментах автоматизации для конфигурационных файлов и даже для определения логики задач автоматизации (см. Ansible).
Вы можете обратиться к этому гайду, чтобы узнать больше о YAML.
Давайте посмотрим, как этот пример вывода команды Cisco IOS show vlan из CLI может быть закодирован с помощью YAML:
vlans:
'1':
interfaces:
- GigabitEthernet3/4
- GigabitEthernet3/5
- GigabitEthernet4/11
mtu: 1500
name: default
said: 100001
shutdown: false
state: active
trans1: 0
trans2: 0
type: enet
vlan_id: '1'
Бонус: коллекция недостатков YAML.
JSON
JSON (JavaScript Object Notation) - это современный формат кодирования данных, определенный в RFC 7159 и широко используемый в веб-интерфейсах API. Он легкий, читаемый человеком и больше подходит для моделей данных современных языков программирования, чем XML.
Вы можете обратиться к этому гайду, чтобы узнать больше о JSON.
{
"vlans": {
"1": {
"interfaces": [
"GigabitEthernet3/4",
"GigabitEthernet3/5",
"GigabitEthernet4/11"
],
"mtu": 1500,
"name": "default",
"said": 100001,
"shutdown": false,
"state": "active",
"trans1": 0,
"trans2": 0,
"type": "enet",
"vlan_id": "1"
}
}
}
Как вы можете видеть, его почти так же легко читать, как YAML, однако родной JSON не поддерживает комментарии, что делает его не очень подходящим для конфигурационных файлов.
Summary
Ниже приведена сводная таблица, представляющая основные свойства описанных форматов данных.
| XML | YAML | JSON | |
|---|---|---|---|
| Читабельность | Не очень | Да | Да |
| Цель | Документация, API | Конфиг. файлы | API`s |
| Python библиотеки | xml, lxml | PyYAML | json |
Существуют онлайн-инструменты, подобные этому, для преобразования данных между всеми тремя форматами.
Technologies
Этот раздел является довольно категоричным и направлен на то, чтобы познакомить вас с основными инструментами, оставив без внимания многие другие, для краткости. Я настоятельно рекомендую взглянуть на список Awesome Network Automation позже.
Python
Python является основным языком программирования, когда речь идет об автоматизации сети. Все популярные инструменты и библиотеки для автоматизации сетей написаны на языке Python.

Обучение основам python не входят в эту статью, в дополнительных источниках указал пару ссылок, по которым учился я.
Cейчас я прохожу тот же путь, пока что осиливаю курс Наташи Самойленко, по которому я собираюсь писать обзорные статьи по заданиям. Если вам не хватало мотивации, то вот она.
Чтобы эффективно использовать Python для решения основных проблем автоматизации сети, вам потребуется освоить этот набор навыков:
- Установка Python в вашей системе
- Использование виртуальных окружений и установка пакетов с помощью pip
- Понимание основных концепций Python, таких как:
- Переменные
- Структуры данных
- Функции
- Импорты (Модули)
Как вы можете видеть, это не слишком сложно, и я рекомендую вам потратить на это время, потому что навыки python существенно упростят изучение автоматизации.
Ways of interacting with network devices programmatically
Существует два основных способа программного доступа к сетевым устройствам: CLI и API.
CLI
Долгое время единственным API сетевых устройств был CLI, который предназначен для использования людьми, а не скриптами автоматизации. Это основные недостатки использования CLI в качестве API:
- Непоследовательный вывод Выводы одной и той же команды могут отличаться в разных версиях NOS (сетевой операционной системы).
- Неструктурированные данные Данные, возвращаемые при выполнении команд в CLI, являются обычным текстом, что означает, что вы должны вручную разобрать их (т.е. CLI scraping)
- Ненадежное выполнение команд Вы не получаете оповещения о выполнении команды и должны разобрать вывод, чтобы определить, была ли команда успешной или неудачной.
Несмотря на то, что все больше и больше сетевых производителей начинают включать поддержку API в свои продукты, маловероятно, что вам не придется иметь дело с CLI во время вашего путешествия по автоматизации сети.
Для разбора вывода CLI используются regular expressions. Мягко говоря, не очень удобная технология.
К счастью, сегодня существует множество инструментов и библиотек, которые облегчают CLI scraping, делая большую часть того, что предлагают регулярки.
“I don’t know who you are. I don’t know what you want. If you are looking for technical help, I can tell you I don’t have any time. But what I do have are a very particular set of regexes. Regexes I have acquired over a very long career. Regexes that are a nightmare for people like you to debug. If you leave me alone now, that’ll be the end of it. I will not look for you, I will not pursue you, but if you don’t, I will look for you, I will find you and I will use them in your code.”
Регулярки знать полезно и если вы совсем их боитесь, то уверяю, этот проект переубедит вас. Попробуйте.
APIs
Если вам повезло и устройства в вашей сети имеют API или, возможно, даже управляются контроллером SDN, этот раздел для вас. Сетевые API делятся на две основные категории: На основе HTTP и на основе NETCONF.
RESTful APIs
REST расшифровывается как Representational State Transfer и определяет набор свойств и ограничений, которым должен соответствовать API, чтобы называться RESTful.

API на основе HTTP могут быть RESTful и не-RESTful. Не-RESTful API на основе HTTP остаются за рамками, поскольку они менее распространены.
RESTful API довольно просты в использовании и понимании, поскольку основаны на протоколе HTTP. По сути, RESTful API - это просто набор HTTP-адресов, по которым вы можете делать GET и/или POST запросы, за исключением того, что возвращаемые данные кодируются в JSON или XML, а не в HTML. Поскольку RESTful API основаны на HTTP, они по своей природе не имеют статического характера. Это означает, что каждый запрос не зависит от другого и должен предоставлять всю необходимую информацию для правильной обработки.
Для изучения RESTful API вы можете использовать такие инструменты, как cURL или Postman, но когда вы будете готовы написать код, использующий RESTful API, вы можете использовать библиотеку Python под названием requests.
В Интернете есть несколько макетов REST API, которые вы можете использовать для практики. Например, kanye.rest и JSONPlaceholder.
NETCONF & RESTCONF
NETCONF это протокол, специально разработанный для управления сетевыми устройствами. В отличие от REST, он использует SSH в качестве транспорта и, как следствие, с сохранением состояния. Другими ключевыми отличиями NETCONF являются четкое разграничение между конфигурационными и операционными данными и концепция хранилищ данных конфигурации.
NETCONF определяет три хранилища данных: running configuration, startup configuration и candidate configuration. Вы, возможно, уже знакомы со всеми тремя из них, в контексте сетевых устройств. Концепция candidate configuration позволяет передавать изменение конфигурации, состоящее из множества команд, в виде одной транзакции. Это означает, что если только одна команда в транзакции завершится неудачно, транзакция не завершится, избегая ситуации, когда применяется частичная конфигурация.
Изучение NETCONF API не такое простое и понятное, как в случае с RESTful API. Для этого необходимо установить интерактивный сеанс SSH на устройстве и отправить длинные команды в XML-кодировке. Для программного доступа к API NETCONF существует библиотека ncclient Python.
RESTCONF - это другой стандартный протокол, который реализует подмножество функциональности NETCONF (например. транзакции не поддерживаются) и использует HTTP в качестве транспорта и является RESTfull.
При выборе между NETCONF или RESTCONF, советуют использовать первый для прямого взаимодействия с сетевыми устройствами, а второй - для взаимодействия с SDN-контроллерами и/или оркестраторами.
gRPC & gNMI
gNMI - это новое дополнение к протоколам сетевого управления, основанное на gRPC от Google и разработанное рабочей группой OpenConfig. Он считается более надежным преемником NETCONF и поддерживает streaming telemetry.
Поскольку gNMI еще не так развит, как NETCONF, он не очень хорошо поддерживается в Python. Хотя есть несколько библиотек, в которые вы можете заглянуть: cisco-gnmii и pygnmi.
Summary
Это сводная таблица, представляющая ключевые свойства типов сетевых API.
| REST | NETCONF | RESTCONF | gNMI | |
|---|---|---|---|---|
| RFC | - | RFC 6241 | RFC 8040 | Draft |
| Transport | HTTP | SSH | HTTP | gRPC (HTTP/2.0) |
| Data encoding | XML, JSON | XML | XML, JSON | ProtoBuf (binary) |
| Transaction support | ❌ | ✅ | ❌ | ✅ |
| Python libs | requests | ncclient | requests | cisco-gnmi, pygnmi |
Git
В этом разделе рассматриваются основы использования и терминология Git. Но сначала я хотел бы остановиться на нескольких причинах, по которым вам стоит обратить внимание на Git и контроль версий.

Why use Git?
- Видимость и контроль Разместив свои скрипты, шаблоны конфигурации или даже конфигурации устройств в Git, вы можете начать отслеживать все изменения и, при необходимости, откатываться к предыдущим версиям.
- Экспериментирование При работе над новой функцией очень удобно создать новую ветку в том же Git-репозитории, а не копировать весь рабочий каталог в новое место.
- Командная работа Рано или поздно вам придется поделиться своей работой с товарищами по команде. Git - это лучший инструмент для совместной работы без необходимости пересылать друг другу копии файлов.
- CI/CD Процессы CI/CD основаны на контроле исходных текстов. Такие события, как commits или branch merging, запускают CI/CD pipeline.
Terminology
Repository
Git-репозиторий - это каталог проекта, содержащий все файлы проекта плюс скрытый каталог с именем .git, где находятся все метаданные Git (история изменений, конфигурация и т.д.). В приведенном ниже примере example-repo - это репозиторий Git.
example-repo
├── .git
│ ├── ...
├── file1
└── file2
Git-репозиторий состоит из трех “деревьев”. Первое - это ваш Working Directory или Working Tree, где хранятся все файлы, с которыми вы работаете. Второе - Index, куда вы помещаете файлы для фиксации, выполняя команду git add, и, наконец, HEAD, который указывает на последнюю, сделанную вами, фиксацию. Index и HEAD хранятся в подкаталоге .git, и вы никогда не взаимодействуете с ними напрямую.
Git-репозиторий может быть локальным или удаленным. Все изменения, которые вы вносите в рабочий каталог, хранятся в локальном хранилище. Синхронизация между локальными и удаленными хранилищами всегда выполняется вручную.
Working directory
Считайте working directory Git’а песочницей, в которой вы вносите изменения в файлы своего проекта. Вот хорошее объяснение из офф. документации:
Наконец, у вас есть working directory (также часто называемый “Working Tree”). Два других дерева хранят свое содержимое эффективным, но неудобным способом - внутри папки .git. В рабочем каталоге они распаковываются в реальные файлы, что значительно облегчает их редактирование. Думайте о working directory как о “песочнице”, где вы можете опробовать изменения, прежде чем зафиксировать их в “staging area” (index) и затем в истории.
Staging
Когда вы хотите внести свои изменения в историю Git, т.е. чтобы сделать commit, вы выбираете, какие файлы вы хотите закоммитить, и вводите git add для них. Таким образом, вы можете отнести изменения в разных файлах к разным коммитам, сгруппировав их по функциям или значению. Постановка также позволяет просмотреть изменения перед их коммитом.
Commit
Commit сохраняет поэтапные изменения в локальном репозитории Git. Он также включает метаданные, такие как автор, дата коммита и сообщение коммита (aka “комментарий”).
Branch
Когда вам захочется добавить новую функцию или провести рефакторинг существующего кода, хорошей идеей будет создать новую ветку, сделать в ней свою работу, а затем слить ее обратно в основную ветку. Это дает вам уверенность в том, что вы не нарушите существующий код. Это также позволяет разным разработчикам работать над одной и той же кодовой базой, не блокируя друг друга.
Ветвление в Git очень легкое и позволяет создавать новые ветки и переключаться между ними практически мгновенно.
Pull (merge) request
Pull (GitHub) или merge (GitLab) запрос - это функция, характерная для веб-менеджеров Git-репозиториев, которая предоставляет простой способ отправить свою работу в проект. Существует много путаницы по поводу того, почему это называется pull request, а не push request, поскольку вы хотите добавить свои изменения в репозиторий. Причина такого наименования проста. Когда вы создаете pull request, вы фактически просите сопровождающего проекта подтянуть(pull) представленные вами изменения в репозиторий.
Basic usage
Command line
Чтобы начать использовать Git в командной строке, я рекомендую взглянуть на этот простой, но полезный гайд для начинающих от Роджера Дадлера.
Dealing with mistakes
В конце концов, вы что-то испортите (например, сделаете commit в неправильной ветке). Для таких ситуаций есть хороший ресурс, который может помочь справиться с распространенными головными болями Git.
.gitignore
Чтобы заставить Git игнорировать определенные файлы или даже подкаталоги, вы можете перечислить их в специальном файле .gitignore. Это чрезвычайно полезно, когда вы хотите, чтобы удаленное хранилище было очищено от временных файлов или файлов, содержащих конфиденциальную информацию (например. пароли).
Docker and containers
Контейнеры для Linux существуют уже довольно давно (а chroot и jail еще дольше), но именно Docker сделал их популярными и доступными.

Контейнеры позволяют запускать программное обеспечение в изолированной среде, но в отличие от виртуальных машин, каждому контейнеру не нужна полноценная ОС для работы. Это делает контейнеры более эффективными с точки зрения использования ресурсов процессора, оперативной памяти и хранилища, не говоря уже о том, что вам не нужно поддерживать отдельную ОС для каждого контейнера, как в случае с виртуальными машинами.
Docker (точнее, Docker Engine) - это программное обеспечение, которое создает, удаляет и запускает контейнеры. Можно считать, что он похож на ESXi. Простота использования Docker сделала контейнеры такими популярными.
До докера так и не добрался, как-то не пришлось к месту ни на работе ни в учебе. Но планирую изучить и эту тему, поэтому пару статей по нему точно будет.
Why use Docker?
Каковы основные причины использования контейнеров в целом:
- Изоляция Приложение, запущенное внутри контейнера, имеет все необходимые ему библиотеки определенных версий. Если другому приложению нужны другие версии тех же библиотек, просто используйте другой образ контейнера.
- Портативность Это вытекает из предыдущего пункта. Если вам удалось запустить свое приложение внутри контейнера, вы можете легко запустить его в любом месте, где установлен Docker, поскольку среда приложения не меняется.
- Масштабируемость Вы можете легко создать множество контейнеров, чтобы распределить нагрузку между ними (см. Kubernetes).
- Производительность Быстрее создаются, быстрее запускаются, потребляют меньше ресурсов.
- Сообщество На dockerhub есть миллионы готовых образов docker, которые вы можете использовать напрямую или создать на их основе свои собственные образы.
Basic Terminology
Для ознакомления с Docker необходимо знать основную терминологию и инструменты.
Тема контейнеризации действительно огромна, и я не хочу углубляться в технические аспекты. Если вы хотите узнать больше о Docker и контейнерах, я могу порекомендовать книгу под названием “Docker Deep Dive” Найджела Поултона.
Images
Продолжая аналогию с виртуальными машинами, можно рассматривать образы Docker как шаблоны виртуальных машин. Образ содержит все необходимые файлы для запуска контейнера и может содержать предопределенные параметры, например, какие TCP-порты должны быть открыты. При запуске контейнера вы можете переопределить эти параметры и добавить свои собственные. Вы можете запускать несколько контейнеров из одного образа. Очень важно понимать, что сами контейнеры являются эфемерными или не имеющими состояния. Это означает, что если вы внесете какие-либо изменения в файловую систему контейнера во время его работы, они не сохранятся после перезапуска контейнера. Если вам требуется постоянство, следует использовать внешние решения для хранения данных, такие как тома (volumes).
Layers
Образы Docker состоят из слоев (layers). По сути, слой - это набор файлов, созданных после выполнения команды в Dockerfile. Если для создания другого образа вы используете те же команды в Dockerfile, Docker просто повторно использует ранее созданный слой. Это ускоряет создание образа и экономит место для хранения.
Tags
Когда вы используете различные версии одного и того же образа, вам нужен способ различать их. Вот тут-то и пригодятся теги. При создании образа или извлечении его из хранилища необходимо указать тег (например. python:3.8.5-slim-buster, где 3.8.5-slim-buster - тег), если вы этого не сделаете, будет использоваться последний (latest) тег. Обратите внимание, что latest не имеет особого значения, это просто тег, который не обязательно обозначает последнюю версию образа.
Volumes
При запуске контейнера вы можете указать каталоги или файлы, которые будут смонтированы в файловой системе контейнера. Каждый такой каталог или файл называется томом (volume). Тома пригодятся, если вам нужно, чтобы данные сохранялись или были совместно использованы различными контейнерами. Это также простой способ вставить пользовательский файл конфигурации в контейнер или использовать контейнер в качестве среды выполнения для вашего сценария, который монтируется внутри контейнера, чтобы вы могли протестировать его без необходимости перестраивать образ контейнера.
Dockerfiles
Dockerfile - это текстовый файл с набором инструкций по сборке образа. Он состоит из команд, определяющих такие вещи как: какой другой образ следует использовать в качестве базового, какие файлы копировать в образ, какие пакеты устанавливать и так далее.
Docker Compose
Docker-compose - это простой оркестратор для контейнеров Docker. Чтобы запустить несколько контейнеров без docker-compose, нужно набрать много длинных команд с множеством аргументов. Docker-compose позволяет указать все эти аргументы в простой и чистой форме YAML-файла. Он также позволяет указывать зависимости между контейнерами, т.е. в каком порядке они должны начинаться. Но даже если вам нужно запустить только один контейнер, лучше написать docker-compose.yml, чтобы записать все эти аргументы.
Docker use cases for network automation
Когда речь идет об автоматизации сети, Docker может пригодиться двумя основными способами:
- Вы можете создавать собственные инструменты автоматизации для запуска в Docker, делая их переносимыми и автоматизируя процесс упаковки.
- Большинство современных инструментов имеют докеризированные версии, которые можно запустить, введя всего одну команду. Этот вариант действительно полезен, когда вы хотите следовать учебнику или опробовать новый инструмент, но не хотите тратить время на настройку (которая может быть весьма нетривиальной).
Вот простой рабочий процесс для создания и запуска собственного контейнера Docker:
- Напишите
Dockerfile - Напишите
docker-compose.ymlфайл - Запустите
docker-compose up
Существует масса статей о том, как писать Docker-файлы и использовать docker-compose. Но я думаю, что сначала вы будете использовать готовые образы, чтобы познакомиться с Docker, и вам нужно будет знать некоторые базовые команды CLI для запуска и остановки, а так же как контролировать контейнеры Docker. Тут хорошая статья об основных командах Docker, которые пригодятся вам на начальных этапах.
Automation Tools
Здесь я хотел бы дать вам краткий обзор наиболее популярных и известных инструментов автоматизации сети.
А вот этот кусочек хорошо зайдет со второй частью статьи Марата - АДСМ6. Интерфейсы взаимодействия с сетевыми устройствами. Которую я все никак не примусь изучать :D
Connection Management and CLI Scraping
Netmiko
Netmiko это библиотека Python, основанная на paramiko и предназначенная для упрощения SSH-доступа к сетевым устройствам. Созданная Кирком Байерсом в 2014 году, эта библиотека Python остается самым популярным и широко используемым инструментом для управления SSH-соединениями с сетевыми устройствами.
Scrapli
Scrapli это несколько новая библиотека python (первый релиз в 2019 году), которая решает те же проблемы, что и Netmiko, но стремится быть “настолько быстрой и гибкой, насколько это возможно”.
Parsing
TextFSM and NTC Templates
TextFSM это модуль Python, созданный компанией Google, целью которого является разбор полуформатированного текста (т.е. вывод CLI). Он принимает на вход файл шаблона и текст и производит структурированный вывод.
NTC templates - это коллекция шаблонов TextFSM для различных поставщиков сетевых решений. TextFSM можно использовать совместно с netmiko и scrapli.
TTP (Template Text Parser)
TTP это новейшее дополнение к инструментам парсинга текста. Он также основан на шаблонах, которые напоминают синтаксис Jinja2, но работают в обратном направлении. Простой шаблон TTP выглядит так же, как и текст, который он должен разобрать, но части, которые вы хотите извлечь, помещаются в ``. В нем нет коллекции готовых шаблонов, но, учитывая относительную простоту его использования, вы можете быстро создать свой собственный.
PyATS & Genie
Эти внутренние инструменты Cisco были публично опубликованы несколько лет назад и продолжают быстро развиваться.
PyATS - это фреймворк для тестирования и автоматизации. В нем много интересного, и я рекомендую вам ознакомиться с ним на ресурсах Cisco DevNet. Здесь я хотел бы остановиться на двух библиотеках в рамках PyATS: Genie parser и Dq.
Первый, как следует из названия, предназначен для разбора вывода CLI и имеет огромную колеекцию (2000+) готовых парсеров для различных устройств (не ограничиваясь Cisco).
Второй, Dq, значительно экономит время, когда вам нужно получить доступ к разобранным данным. Часто парсеры, такие как Genie, возвращают данные в сложных структурах данных (например. вложенные словари), и чтобы получить доступ к чему-то, вам понадобятся четкое понимание того, где искать. С помощью Dq вы можете делать запросы, не особо заботясь о том, где во вложенной структуре находятся ваши данные.
Configuring devices
NAPALM
NAPALM (Network Automation and Programmability Abstraction Layer with Multivendor support) - это библиотека Python, которая реализует набор функций для взаимодействия с различными операционными системами сетевых устройств с использованием унифицированного API.
Supported devices
На момент написания статьи NAPALM поддерживал следующие сетевые операционные системы:
- Arista EOS
- Cisco IOS
- Cisco IOS-XR
- Cisco NX-OS
- Juniper JunOS
Так же есть комьюнити драйвера на github.
Working with device configuration
С помощью NAPALM вы можете передавать конфигурации и получать рабочие данные с устройств. При манипулировании конфигурацией устройства у вас есть два варианта:
- Replace всю текущую конфигурацию на новую
- Merge существующую текущую конфигурацию с новой конфигурацией
Операции замены и слияния не применяются сразу. Перед фиксацией новой конфигурации вы можете сравнить ее с текущей конфигурацией, а затем либо зафиксировать, либо отменить. И даже после применения новой конфигурации у вас есть возможность откатиться к ранее зафиксированной конфигурации, если сетевая ОС поддерживает это.
Я успел опробовать NAPALM (в Netbox он встроен почти из коробки) на SG коммутаторах Cisco, использовав, как раз, комьюнити драйвер. Интересный инструмент
Validating deployment
Возможность получения оперативных данных с устройств обеспечивает мощную функцию NAPALM, называемую отчетом о соответствии или deployment validation. Чтобы получить отчет о соответствии, необходимо написать YAML-файл, описывающий желаемое состояние устройства, и указать NAPALM использовать его против устройства с помощью метода compliance_report.
Integration with other tools
Будучи библиотекой Python, NAPALM может использоваться непосредственно в сценариях Python или интегрироваться с Ansible (модуль napalm-ansible), Nornir (плагин nornir_napalm) или SaltStack (встроенная поддержка).
Ansible
Ansible это комплексный фреймворк автоматизации, изначально разработанная для обеспечения серверов Linux. Благодаря своей безагентной природе, Ansible вскоре стал очень популярен среди сетевых инженеров. В отличие от систем на основе агентов, таких как Chef и Puppet, Ansible выполняет код Python на целевых системах для выполнения своих задач. Поэтому он требует только наличия на целевой системе SSH и Python. Но как это согласуется с сетевыми устройствами, которые не могут выполнять код Python? Для решения этой проблемы Ansible выполняет свои сетевые модули локально на control node.
Ansible Galaxy
Для взаимодействия с различными сетевыми платформами Ansible использует плагины, объединенные в коллекции. Для установки этих коллекций вы можете использовать Ansible Galaxy, которая представляет собой что-то вроде DockerHub или PyPi для Ansible, где пользователи могут совместно использовать роли и плагины Ansible.
Terminology
Типичный проект автоматизации Ansible состоит из следующих составляющих.
Inventory
В файле Inventory перечислены управляемые сетевые устройства, их имена хостов или IP-адреса, а также, по желанию, другие переменные, например, учетные данные доступа. Ansible может использовать Netbox в качестве источника инвентарной информации с помощью plugin.
Playbooks
Playbook определяет упорядоченный список задач, которые должны быть выполнены на управляемых устройствах. Он также может определять, какие роли должны применяться к устройствам.
Roles
Роли Ansible - это, по сути, плейбуки, разбитые на известные файловые структуры.
Роли позволяют группировать задачи и переменные в отдельные каталоги. Это делает проект Ansible более организованным и позволяет вам легче использовать эти роли для различных групп управляемых хостов.
Вы можете создавать роли в соответствии с различными разделами конфигурации: один для маршрутизации, другой для основных настроек, таких как NTP и DNS-серверы и т.д. и т.д. Затем вы можете применить эти роли к различным группам устройств. Например, маршрутизация нужна только на основных коммутаторах, а базовые настройки должны применяться ко всем устройствам.
Pros & Cons
Ansible использует свой собственный DSL, основанный на YAML, для описания логики своих плейбуков. Это дизайнерское решение можно считать палкой о двух концах. Он требует минимального обучения для решения простых задач, но когда вам нужно написать что-то более сложное, он быстро становится довольно громоздким и трудно отлаживаемым.
Скорость и масштабируемость - это другие аспекты, в которых Ansible не блещет в контексте автоматизации сети.
На мой взгляд, Ansible - это отличная отправная точка в вашем путешествии по автоматизации сети, поскольку он прост в освоении и дает вам хорошее представление о том, что представляют собой современные инструменты автоматизации. Как сказал Джон МакГоверн из CBT Nuggets, “Ansible - это как CCNA для автоматизации сети”.
Еще одним преимуществом Ansible является то, что его можно использовать как единое решение для автоматизации всей ИТ-инфраструктуры.
Nornir
Изначально Nornir был создан Дэвидом Баррозо, автором NAPALM.
Nornir - это фреймворк автоматизации, написанный на языке python для использования с python.
Последняя часть определения является здесь ключевой. В отличие от Ansible, Nornir использует чистый Python для описания своих задач (задачи Nornir - это, по сути, функции Python). Это делает Nornir гораздо более гибким, быстрым и простым в дебаге.
Еще один аспект того, что Nornir - это чисто Python, заключается в том, что, изучая Nornir, вы также изучаете Python.
Nornir - это подключаемая система, и начиная с версии 3.0 она поставляется только с самыми основными плагинами. Список плагинов Nornir можно найти тут. Плагины устанавливаются с помощью стандартного менеджера пакетов Python pip.
Как и в Ansible, в Nornir есть концепция инвентаризации, которая также может быть записана в YAML (плагин YAMLInventory), где вы размещаете переменные хоста и группы. Вы также можете использовать существующие файлы инвентаризации Ansible (nornir_ansible) или получить информацию об инвентаризации непосредственно из Netbox с помощью nornir_netbox.
Для взаимодействия с сетевыми устройствами Nornir может использовать библиотеки NAPALM, netmiko и scrapli с помощью соответствующих плагинов.
Я, к слову, решил изучать Nornir т.к привлекла идея чистого Python. Поэтому Ansible я пропустил. Но, видимо, его тоже придется затронуть в будущих статьях :)
Summary
Все описанные инструменты имеют свои преимущества и варианты использования. Я бы рекомендовал начать с более высокоуровневых инструментов, таких как NAPALM, Ansible или Nornir.
Text editors
Текстовый редактор - это часть программного обеспечения, с которым вы будете проводить большую часть времени при автоматизации сетей. Здесь я хотел бы сделать обзор самых популярных современных текстовых редакторов.
VS Code
Хорошо это или плохо, но сегодня на рынке текстовых редакторов явно доминирует Visual Studio Code. У него отличная и постоянно расширяющаяся коллекция плагинов, приятный пользовательский интерфейс, встроенная поддержка Git, интеллектуальное завершение кода, да мало ли что еще.
VS Code - это бесплатный текстовый редактор с открытым исходным кодом, созданный на базе Electron и принадлежащий компании Microsoft. Первоначально он был выпущен в 2015 году.
Atom
Atom - еще один высоконастраиваемый текстовый редактор с открытым исходным кодом, созданный GitHub. Поскольку GitHub был приобретен компанией Microsoft, Atom теперь также является продуктом Microsoft.
Atom также является бесплатным, с открытым исходным кодом и построен на базе Electron. Первоначально он был выпущен в 2014 году.
Атом прекратил свое существование в 2022 году
VIM
Вместо Атом, я добавлю немного про VIM, с которым познакомился еще админя сервера на линуксе. А по настоящему влюбился у Наташи на курсе.
VIM - мощный текстовый редактор с полной свободой настройки и автоматизации, возможными благодаря расширениям и надстройкам.
Хотите сделать из него полноценную IDE как VS Code? Пожалуйста
По моему опыту, VIM - инструмент на любителя. НО вы должны хотя бы раз попробовать зайти дальше изучения команды q!.
Vim рекомендую начать изучать отсюда.
PyCharm
PyCharm - это полноценная среда разработки Python от JetBrains. Я слышал много хвалебных отзывов о нем в контексте разработки на Python, но сам никогда не пробовал. PyCharm поставляется в двух версиях: полнофункциональная Professional (лицензия по подписке) и менее функциональная, но бесплатная Community Edition (разработка только на Python).
Sublime Text
Sublime - самый старый текстовый редактор в этом списке. В нем есть такие замечательные функции, как многострочное редактирование и “Go To Anything”. команда, позволяющая быстро перейти к определенной части текста на любой открытой вкладке. Он также может быть расширен с помощью плагинов, но менеджер пакетов не включен по умолчанию, и вам придется сначала установить его вручную.
Sublime Text - это проприетарное платное программное обеспечение, написанное на C++ и первоначально выпущенное в 2008 году. Она имеет 30-дневный пробный период. После этого вам время от времени будут напоминать о необходимости приобрести лицензию.
Summary
Освоение нового текстового редактора со всеми его ярлыками и плагинами - это долгосрочная инвестиция времени. Если вы не пользовались ни одним из этих текстовых редакторов, я рекомендую выбрать VS Code как наиболее перспективное и хорошо продуманное решение.
Если говорить совсем о новичках, есть еще редактор Mu, о нем отлично рассказано у Наташи в блоге.
Conclusion
Я надеюсь, что это руководство дало вам хороший обзор ландшафта автоматизации сетей. Если вы решите узнать больше, я советую вам создать лабораторию и начать практиковаться. Затем, когда вы будете готовы применить свои новые навыки в повседневной работе, я рекомендую простой старт. Например, вы можете автоматизировать сбор информации с ваших сетевых устройств (например. config backup), а затем, когда вы почувствуете себя более комфортно, начните конфигурировать устройства программно.
Эту часть я планирую развивать у себя на канале, будет практика, стримы и т.п
Social Media Resources
Люди, на которых можно подписаться в Twitter:
- @ccurtis584
- @damgarros
- @danieldibswe
- @dbarrosop
- @dmfigol
- @IPvZero
- @jeaubin5
- @jedelman8
- @jstretch85
- @kirkbyers
- @lykinsb
- @mirceaulinic
- @natenka_says
- @networktocode
- @ntdvps
- @nwkautomaniac
- @rickjdon
- @simingy
- @tahigash3
- @vanderaaj
References and further reading
- Network Programmability and Automation a book by Jason Edelman, Scott S. Lowe, Matt Oswalt
- Hands-on with NetDevOps by Julio Gomez
- What is NetDevOps? by Rick Donato
- A practical approach to building a network CI/CD pipeline by Samir Parikh
- NetDevOps: what does it even mean? by Madison Emery (Cumulus Networks)
- Awesome Network Automation — curated Awesome list about Network Automation
- 6 Docker Basics You Should Completely Grasp When Getting Started by Vladislav Supalov
- First Steps With Python by Derrick Kearney
- Python Cheatsheet — handy one-page website with examples
- Fluent Python — a book by Luciano Ramalho
- Learning Python — a free email Python course by Kirk Byers specifically intended for network engineers
- Python Programming Language - free programming certification course
- Data Structures And Algorithms In Python — a video tutorial by Dhaval Patel
Все изображения взяты из оригинала статьи, где присутствую все ссылки на исходники.
Подводя итог, из этой статьи, в свое время, я узнал много нового, надеюсь, ее переводом я кому-то помог переступить барьер в понимании существующих технологий автоматизации или побудил изучать подобного рода материалы, которые достаточно часто остаются не переведенными.
Отдельное спасибо Дмитрию за труды и предоставленную возможность опубликовать перевод.
Хочешь обсудить тему?
С вопросами, комментариями и/или замечаниями, приходи в чат или подписывайся на канал.